
Книга: Основы Инженерии данных. Глава 1. Описание дата-инженерии.

Дата публикации: Июнь 2022 год
Издатель: O’Reilly Media, Inc.
Ссылки на покупку: amazon, ozon
Дисклеймер: Целью данной статьи не является полностью пересказать содержание книги, а лишь выделить важные аспекты в более сжатом и понятном формате. Я рекомендую к ознакомлению с полной версией книги. Учитывая, что книга издана только на английском языке, я мог допустить неточности и ошибки в переводе и исказить смысл содержания заложенный авторами.
Кем написана?
Эту книгу написали бывшие data scientist’ы. Они столкнулись с трудностями в Data Science проектах из-за отсутствия фундаментальных знаний в инженерии данных.
Что не покрывает?
Эта книга не посвящена конкретным технологиям, инструментам или платформам в инженерии данных. Много хороших книг охватывают эти аспекты, но они быстро устаревают. В этой книге рассматриваются фундаментальные концепции дата-инженерии.
О чем?
Эта книга заполняет пробелы в материалах по инженерии данных. В то время как многие ресурсы описывают конкретные технологии, трудно понять, как их эффективно использовать для решения задач бизнеса. Книга охватывает все этапы работы с данными и показывает, как использовать технологии для нужд аналитиков, data scientist’ов и инженеров машинного обучения.
Главная идея книги — жизненный цикл работы с данными: создание, хранение, сбор, преобразование и предоставление данных. Несмотря на технологии, эти этапы остаются неизменными уже много лет.
Для кого?
Основная аудитория книги — специалисты уровня middle и senior, разработчики, аналитики, data scientist’ы, стремящиеся стать инженерами данных, а также дата-инженеры, желающие всестороннего развития. Книга также подойдет менеджерам, лидам data-команд и руководителям DWH, планирующим миграцию с on-premise на облако.
Что вы узнаете?
— Как инженерия данных влияет на вашу текущую роль в компании
— Как среди тысяч технологий выбирать наиболее подходящие для решения ваших задач, для построения дата-архитектур
— Как использовать жизненный цикл работы с данными для создания надежной архитектуры
— Узнаете лучшие практики для каждого этапа жизненного цикла работы с данными
— Внедрите принципы инженерии данных в вашу текущую роль
— Объедините различные облачные технологии, чтобы удовлетворить потребности конечных пользователей
— Внедрите управление данными и безопасность на всех этапах жизненного цикла работы с данными
Что такое инженерия данных?
Инженерия данных — одна из самых востребованных областей в сфере данных, технологиях, и не без причины. Она закладывает основу для data science и аналитики в production среде. В данной главе узнаем о том что такое инженерия данных, как она родилась и эволюционировала и с кем они работают в компаниях.
Инженерия данных — это разработка, внедрение и поддержка систем и процессов, которые обрабатывают сырые данные и превращают их в высококачественную, согласованную информацию для решения задач аналитики и машинного обучения. Инженерия данных идет бок о бок с безопасностью, управлением данными, DataOps, архитектурой данных, оркестрацией и software engineering. Инженер данных управляет жизненным циклом работы с данными, начиная с получения данных из исходных систем и заканчивая предоставлением данных для аналитики или машинного обучения.
Эволюция инженера данных
1980 — 2000 года, от хранилища данных к вебу
Понятие хранилища данных возникло в 1980-х годах благодаря Биллу Инмону. После создания реляционных баз данных и SQL разработчиками IBM, компания Oracle популяризировала реляционные БД. Ральф Кимбал и Билл Инмон разработали методы описания бизнес-моделей в хранилищах данных, которые активно используются до сих пор.
Хранилища данных стали основой масштабируемой аналитики с использованием MPP баз данных, что привело к появлению ролей BI инженера, ETL и DWH разработчика — предков современных инженеров данных.
В середине 1990-х годов интернет стал популярным благодаря компаниям с web-first подходом, таких как AOL, Yahoo и Amazon. Популяризация интернета привела к генерации больших объемов данных в веб-приложениях, в то время как вендоры предлагали на рынке монолитные системы с дорогими лицензиями, которые не были способны обрабатывать такие объемы данных.
2000-ые, рождение современной инженерии данных
В начале 2000-х годов компании Yahoo, Google и Amazon, выросшие в крупные технологические компании, столкнулись с проблемами традиционных систем, не справлявшихся с большими объемами данных. Требовались системы нового поколения, которые были бы экономичными, масштабируемыми, надежными и доступными.
Параллельно большому буму данных значительно подешевели цены на серверы, RAM, жесткие диски и флеш-накопители, что способствовало развитию распределенных вычислений и хранения данных, привело к созданию децентрализованных систем и началу эры больших данных.
В эти же годы появились такие системы как Hadoop, Amazon DynamoDB, сервис AWS, который стал первым публичным облачным сервисом c бизнес моделью плати за использование вычислительных систем, хранение данных в облаке. Вместо приобретения физических компонент, серверов, разработчикам предлагалось арендовать вычислительные системы и хранение данных у AWS. Данная модель стала настолько прибыльной, что вскоре появились и другие облачные сервисы как Google Cloud, Microsoft Azure, DigitalOcean. Публичные облака вероятно стали самой значимой инновацией 21-ого века, которая устроила революцию в разработке и развертывании приложений.
Публичные облака и первые инструменты обработки больших данных стали фундаментом современного ландшафта инженерии данных.
2000 — 2010ые: инженерия больших данных
Инструменты из экосистемы Hadoop быстро развивались и распространялись по всему миру. Помимо пакетной обработки данных появилась событийная обработка данных — потоковая обработка. Традиционные GUI-ориентированные инструменты уступили место инструментам с code-based подходом.
Инженерам данных, помимо того что нужно было иметь навыки в разработке ПО, приходилось поддерживать большие кластеры серверов для обеспечения эффективной работы инструментов из экосистемы Hadoop (YARN, Hadoop Distributed File System (HDFS), MapReduce). Поддержка таких кластеров требовала больших команд и значительных затрат, что не всегда приносило ценность для бизнеса.
Поэтому необходимо было найти возможности создать новые абстракции, упростить администрирование и поддержку big-data инфраструктуры, сделать инструменты обработки данных более доступными.
В результате, с появлением облачных сервисов, обработка больших данных стала обычным делом для многих компаний, и фокус инженеров сместился с разработки технологий на доставку данных потребителям.
2020-ые: инженерия для жизненного цикла работы с данными
Исторически дата-инженеры использовали такие монолитные фреймворки как: Hadoop, Spark, Informaticа, но сейчас наблюдается тренд к децентрализованным, модульным и абстрагированным инструментам.
Инженерия данных становится дисциплиной по интеграции различных технологий для достижения бизнес-целей. В то время как от инженера данных требовались навыки низкоуровневого программирования, они все больше и больше находят себя в роли, сфокусированных на вещах, находящихся выше в иерархии ценностей, таких как: безопасность, управление данными, DataOps, архитектура данных, оркестрация и в целом управление жизненным циклом данных.
Инженерия данных и Data Science
Инженерия данных — это отдельная от data science и аналитики область. Они дополняют друг друга, но они разные. Дата-инженеры обеспечивают входные данные для data scientist’ов, они же конвертируют эти входные данные во что-то полезное.
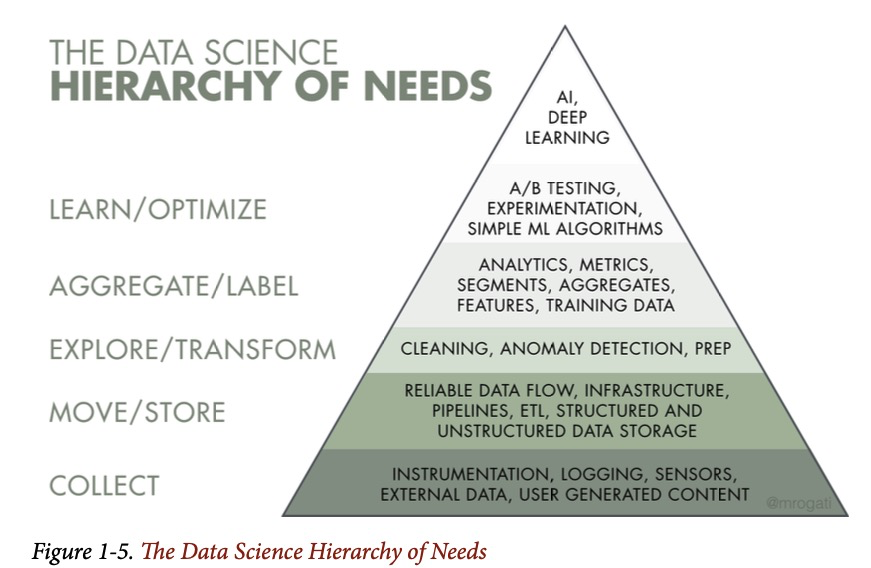
Многие data scientist’ы тратят 70-80% своего рабочего времени на сбор, очистку и обработку данных, а не на аналитику и машинное обучение. Monica Rogati в своей статье 2017 года критикует компании, за то, что прежде всего им нужно построить солидный фундамент данных (первые 3 нижних слоя в иерархии потребностей) перед тем как начать заниматься AI и ML.
В идеальном мире data scientist’ы должны проводить около 90% своего рабочего времени, сфокусировавшись на верхних 3 слоях в иерархии потребностей. В то время как дата-инженеры сфокусированы на нижних 3 частях. Мы считаем, что роль дата инженеров так же важна, как и роль data scientist’ов, для успешных проектов Data Science.
Зрелость данных в компании
Уровень сложности инженерии данных во многом зависит от степени зрелости данных в компании. Зрелость данных — это процесс совершенствования в использовании и интеграции данных в рамках всей организации. Существует три этапа зрелости данных:
- Начало работы с данными
- Масштабирование данных
- Лидерство на основе данных
Этап 1: Начало работы с данными
В этот момент у компании могут быть нечетко поставленные цели или они вовсе не определены, архитектура данных и инфраструктура находятся на стадии планирования. Команда маленькая, и дата-инженер часто совмещает несколько ролей. Цель дата-инженера — быстро двигаться, адаптироваться и приносить ценность.
На этом этапе уже существует желание получать инсайты из данных, но сотрудники не знают как эффективно использовать данные. Большинство запросов от бизнеса — это разовые запросы (ad-hoc запросы).
На этом этапе дата-инженеру стоит сфокусироваться на следующих вещах:
— Заручитесь поддержкой от заинтересованных лиц, включая руководителей уровня C, по вопросам дизайна и построения архитектуры данных
— Определитесь с правильной архитектурой данных. Зная бизнес-цели должно быть понятно какие бенефиты компания стремится получить используя данные
— Постройте солидный фундамент данных для будущих аналитиков данных, data scientist’ов, чтобы генерировать отчеты и строить ML модели, которые принесут выгоду организации
Данный этап может содержать множество подводных камней. Вот некоторые советы чтобы их избежать:
— Показывайте важность данных в организации через достижение быстрых побед, например, показав как используя данные можно принести больше прибыли, но помните, быстрые решения могут порождать технический долг
— Стройте взаимодействие с другими департаментами и избегайте изоляции
— Используйте готовые решения там где это возможно
— Создавайте кастомные решения только когда это приносит конкурентное преимущество
Этап 2: Масштабирование c данными
На данном этапе компания уже не делает разовые (ad-hoc) запросы по данным, внедрила формализованные практики работы с данными. Теперь одним из вызовов заключается в создании масштабируемых архитектур данных и планировании будущего, где компания уже будет принимать решения, стратегии основываясь на данных, так называемый data-driven подход. Роли инженерии данных теперь не совмещает сразу несколько ролей, специалисты сосредоточены на конкретных частях жизненного цикла работы с данными.
На этом этапе зрелости данных целью дата инженера является:
— Создать формализованные практики работы с данными
— Создать надежную, масштабируемую архитектуру данных
— Внедрить принципы DevOps, DataOps в компанию
— Построить инфраструктуру, платформы, которые позволят разрабатывать, разворачивать, управлять ML моделями
— Быть сфокусированными над существующими решениями, являющимися стандартом индустрии для решения обычных задач, вместо того чтобы разрабатывать все с нуля
Потенциальные проблемы с которыми можно столкнуться на данном этапе:
— С ростом объема данных в компании появляется соблазн внедрять технологии, которые популярны в компаниях из Кремниевой долины. Не стоит искушаться соблазну, любая технология должна быть выбрана с целью принести ценность вашим клиентам
— Узкое место по масштабированию это не кластер серверов, хранилища или технологии — это команда дата инженеров. Используйте решения, которые просто разворачивать и управлять
— Коммуницируйте с другими команда на тему практического применения данных. Учите организацию как потреблять и извлекать ценность из данных
Этап 3: Лидерство на основе данных
На этом этапе компания уже считается data-driven (все решения принимаются основываясь на данных). Автоматизированные потоки данных и системы разработанные дата инженерами позволяют сотрудникам проводить аналитику и ML самостоятельно. Подключение новых источников данных происходит бесшовно. Дата-инженеры внедрили меры мониторинга и практики для того чтобы данные были всегда доступны для потребителей и систем.
На этом этапе зрелости данных дата-инженеры должны придерживаться следующего:
— Создавать автоматизации для бесшовной презентации и использования новых данных
— Сфокусироваться на построении кастомных инструментов и систем для извлечения ценности из данных как конкурентное преимущество
— Сконцентрируйтесь на аспектах данных, которые используются в больших корпорациях, например, управление данными, качество данных, data governance, DataOps
— Разверните инструменты, позволяющих проследить зависимости данных сквозь всю организацию, такие как каталог данных, data lineage, система по управлению метаданных
— Создайте сообщества, окружающую среду, где люди могут сотрудничать и говорить открыто независимо от занимаемой должности
Проблемы с которыми можно столкнуться на данном этапе:
— Как только организация дошла до данного этапа она постоянно должна держать фокус на поддержке текущего уровня, продолжать улучшаться, чтобы нивелировать риск скатиться на этап ниже
— На этом этапе все больше соблазнов попробовать модные технологии, которые не принесут ценности бизнесу. Разрабатывайте кастомные технологии только если это будет вашим конкурентным преимуществом
Континуум ролей инженерии данных, от точки А до B
Зрелость данных служит полезным ориентиром для понимания вызовов, с которыми компания сталкивается в процессе своего роста. В зависимости от уровня зрелости компании ей могут понадобиться разные дата-инженеры для решения задач:
— Тип А:
Дата инженер типа А сосредоточен на абстракциях, использует готовые решения и управляет сервисами для упрощения архитектуры данных и избегает излишней сложности.
— Тип B:
Дата-инженеры типа B сосредоточены на разработке собственных инструментов обработки данных и масштабируемых систем, опираясь на ключевые компетенции и конкурентные преимущества компании. Они часто встречаются в более зрелых организациях.
Инженеры типов А и B могут работать вместе или быть одним и тем же человеком. Обычно компании начинают с найма инженеров типа А, а затем переходят к навыкам типа B по мере необходимости.
Дата-инженеры и другие технические роли
Дата-инженеры — это хаб между производителями данных, например, как software engineer, архитекторами данных, DevOps и потребителями данных, например, как аналитики данных, data scientists, ML инженеры.
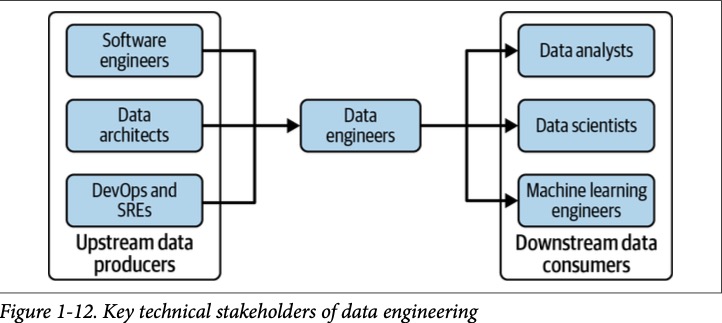
Производители данных:
Архитекторы данных
Архитекторы данных работают с высоким уровнем абстракции, имея большой инженерный опыт за плечами, они проектируют план для управления данными всей организации, связывая процессы компании и в целом архитектуру данных и систем. Они также являются неким мостом между техническими специалистами и заинтересованными лицами из бизнеса.
Архитекторы данных ответственны за внедрение политик управления данными для разных департаментов, команд и бизнес юнитов всей организации. Они определяют глобальные стратегии по управлению данных и их контроля. Руководят основными инициативами, такими как миграция на облачные решения или проектирования облачной архитектуры.
С появлением облачных сервисов архитекторы данных стали более гибкими по сравнению с традиционными on-premise системами. Решения для on-premise систем, которые требовали длительного планирования, контрактов на закупку, установки оборудования , сейчас принимаются в процессе реализации как один из этапов более широкой стратегии. Тем не менее, архитекторы данных остаются влиятельными визионерами в компаниях, тесно взаимодействуя с дата инженерами, чтобы определить большую общую картину архитектурных практик и стратегий по работе с данными.
В зависимости от зрелости компании и ее размеров дата-инженеры могут забирать на себя обязанности архитектора данных. Поэтому дата инженер должен иметь отличное понимание лучших архитектурных практик и подходов.
Software Engineers
Software engineers разрабатывают приложения и системы, которые позволяют бизнесу компании функционировать. В большинстве своем они ответственны за генерацию данных, которые являются для дата-инженеров одним из главных источников. Системы, которые разрабатывают software engineers обычно генерируют данные в виде событий приложения и логов, которые являются сами по себе очень полезным активом. Software engineers и дата-инженеры взаимодействуют начиная от старта нового проекта до проектирования данных приложения с целью потребления, обработки их для аналитики и ML сервисов.
Дата-инженерам стоит тесно взаимодействовать с software engineers, чтобы понимать какого типа данные генерируют их приложения, какого объема, частоты, формата и все остальное что может повлиять на жизненный цикл данных, как например, безопасность и соответствие регуляторным требованиям.
DevOps Engineers и SRE
DevOps и SRE часто создают данные через операционный мониторинг. Мы классифицируем их как производители данных для дата-инженеров, но они могут быть и потребителями данных от дата-инженеров, потребляя данные через дашборды или взаимодействуя с дата инженерами напрямую в координации работы системы данных.
Потребители данных:
Data Scientists
Как уже упоминалось, многие Data Scientists тратят 70-80% рабочего времени на сбор, очистку и подготовку данных, что свидетельствует о недостаточной развитости практик дата-инженерии в командах. Популярные фреймворки Data Science могут стать узкими горлышками если их не масштабировать должным образом. Data Scientists, работающие на одной рабочей машине, вынуждены работать с небольшим по объему данными, тем самым значительно усложняя подготовку данных и потенциально идя на компромисс с качеством разрабатываемой модели. Кроме того, их написанный код и локальная среда окружения часто сложно развернуть в продакшен. Если дата-инженеры выполняют свою работу, то DSерам не нужно было бы тратить свое время на сбор, очистку и подготовку данных после первоначального анализа данных. Дата-инженеры должны максимально автоматизировать этот процесс.
Потребность в данных, готовых к продакшен среде, — это значительный фактор почему профессия дата инженера существует. Работа дата инженеров обеспечить автоматизацию предоставления данных и их масштабирование, что делает проект Data Science более эффективным.
Data Analysts
Data Analysts сфокусированы на понимании эффективности бизнеса и его трендов, анализируя данные в прошлом и настоящем. Для аналитики они используют SQL в корпоративных хранилищах данных или озерах данных, Excel, инструменты визуализации такие как PowerBI, Tableau, Looker. Data Analysts обладают глубокой экспертизой в данных бизнес домена, понимая их происхождение, основные характеристики и метрики. Их основная работа заключается в предоставлении инсайтов бизнес домена для управляющих менеджеров с целью принятия стратегических решений.
Дата-инженеры взаимодействуют с data analysts, чтобы обеспечить им доступ к новым источникам данных необходимых бизнесу. Экспертиза data analysts играет ключевую роль в улучшении качества данных. Работая с дата инженерами, они подсвечивают какие проблемы и неточности нужно исправить в данных.
Machine Learning engineers
ML инженеры тесно работают с дата инженерами и data scientistами, часто делят между собой задачи и обязанности. Основной фокус ML инженеров в разработке продвинутых методов машинного обучения, тренировке моделей, поддержка инфраструктуры для обеспечения работы ML процессов в масштабируемых продакшен средах. Помимо ML-фреймворков они часто работают с фреймворками глубокого обучения, такими как PyTorch и TensorFlow.
ML инженеры обладают знаниями об оборудовании, сервисах и системах необходимых для работы ML фреймворков для обучения ML моделей и развертывания в продакшен среде. Они часто работают в облачных средах, где могут настроить и отмасштабировать инфраструктуру по мере необходимости. Сфера ML инженерии развивается быстрыми темпами с уклоном в MLOps, который заключается во внедрении лучших практик от software engineers и DevOps.