
Apache Spark

Apache Spark — это универсальный, высокопроизводительный, отказоустойчивый движок, написанный на Scala, для распределенной обработки данных.
Универсальный
Spark способен работать с различными видами обработок данных:
— batch обработка
— ad-hoc запросы
— циклические алгоритмы (нужно запускать часть команд раз за разом итеративно)
— streaming обработка
Высокопроизводительный
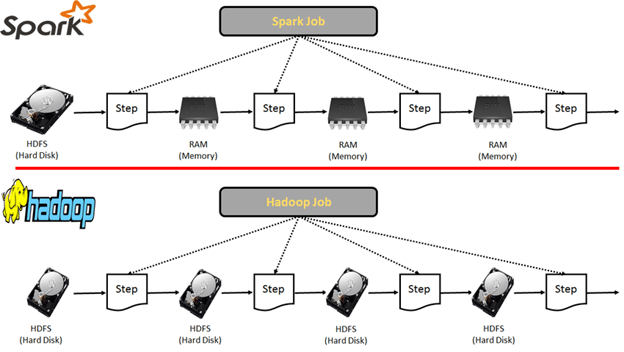
Spark способен выполнять вычисления в оперативной памяти, но и с дисковой памятью он работает эффективно. Чтобы применить вычислительные преимущества Spark ему нужно выполняться на кластере серверов, а это значит, что необходима поддержка горизонтального масштабирования — разбиение системы на более мелкие структурные компоненты и разнесение их по отдельным физическим машинам, параллельно выполняющие одно и то же задание.
Отказоустойчивый
Spark в случае нехватки оперативной памяти для вычислений выполнит так называемый spill данных с оперативной памяти на диск тем самым работа Spark приложения не приостановится, но сильно замедлится.
spill — это термин для обозначения процесса перемещения данных из оперативной памяти на диск, а затем обратно в оперативную память.
С какой целью создали Apache Spark?
Spark был создан для устранения ограничений MapReduce у Hadoop за счет:
— обработки данных в оперативной памяти
— уменьшения кол-ва шагов в задании
— повторного использования данных в нескольких параллельных операциях
Spark требуется только один шаг чтения данных с диска в память, а затем выполняются операции трансформации данных и записываются результаты во внешние системы хранения. Использование оперативной памяти и сокращение числа операций с данными приводит к гораздо более быстрому выполнению заданий нежели как у Hadoop.
Spark также умеет повторно использовать наборы данных, помещенные в кэш памяти, чтобы значительно ускорить алгоритмы машинного обучения, которые многократно вызывают функцию в одном и том же наборе данных.
Кэширование данных — это высокоскоростной уровень хранения, на котором требуемый набор данных необходим временно. Доступ к данным на этом уровне осуществляется значительно быстрее, чем к основному месту их хранения. С помощью кэширования становится возможным эффективное повторное использование ранее полученных или вычисленных данных.
Работа Spark с данными в оперативной памяти влечет за собой риски по их потере, так как они будут стерты в случае если пропадет электричество или что-то пойдет не так с самими нодами.
Когда нужно использовать Apache Spark?
— Параллельная обработка больших распределено хранящихся наборов данных
— Выполнение интерактивных ad-hoc запросов для изучения и визуализации наборов данных
— Построение сквозных конвейеров (ETL) обработки данных из различных источников
— Обработка потоков данных в режиме реального времени
— Создание и обучение моделей машинного обучения
— Анализ графов и соц сетей
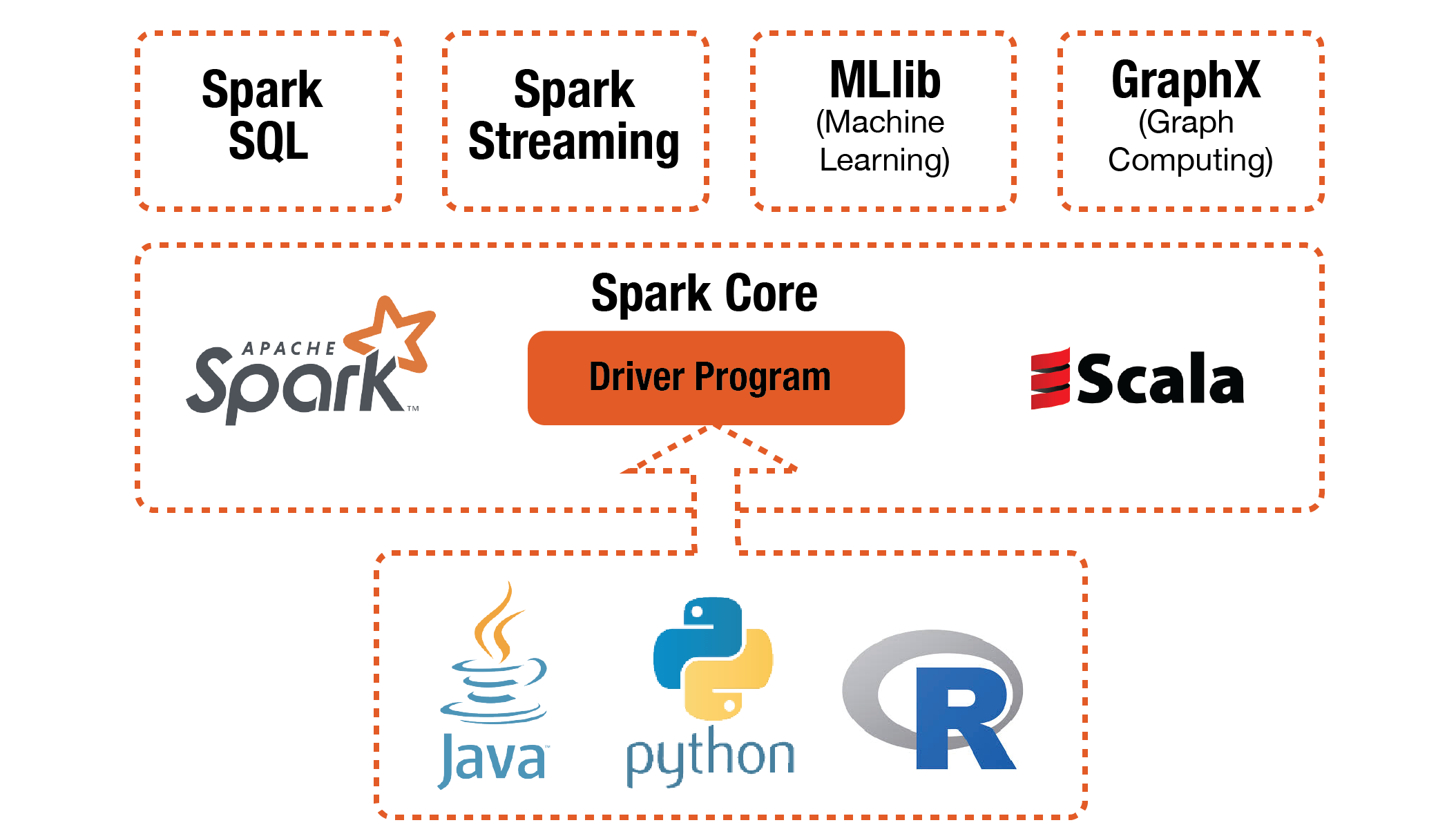
Основные компоненты Apache Spark
Spark Core — основная библиотека, главный движок спарка, который занимается: поддержкой API, управлением памятью, распределением нагрузки, параллельностью запросов, взаимодействием с внешними системами хранения.
Spark SQL and DataFrames — библиотека унифицирует работу со структурированными данными, поддержка языка SQL.
Spark Streaming — библиотека потоковой обработки данных, не совсем реал тайм, а скорее микробатчинг.
RDD (Resilient Distributed Dataset) — самая низкоуровневая единица в иерархии модели Spark, представляет собой распределенный неизменяемый набор данных, который делится на множество частей, обрабатывающихся различными узлами в кластере. Когда использовать RDD:
— когда какая-то внешняя библиотека использует RDD
— детальная оптимизация кода, когда с помощью DataFrame уже не получается
— когда нужно давать Spark’у точные инструкции как нужно выполнять запросы с данными
Spark MLlib — это библиотека фреймворка Apache Spark, позволяющая реализовывать механизм машинного обучения (Machine Learning, ML) и решать задачи, связанные с построением и обучением ML-моделей.
Spark GraphX — это компонент Apache Spark, специализирующийся на анализе графов. Графовые структуры широко используются в различных областях, таких как социальные сети, транспортные системы, биоинформатика и многое другое
Catalyst Optimizer — оптимизатор плана запроса. Catalyst — это дерево, состоящее из узловых объектов. Каталист выполняет следующие шаги для оптимизации:
— Анализ — определить тип каждого передаваемого столбца и действительно ли существуют столбцы, которые вы используете
— Логическая оптимизация (логический план составляет дерево, которое описывает, что нужно сделать). Добавляется predicate-pushdown (добавление фильтра where в условие для внешних источников). Predicate-pushdown поддерживается у JDBC источников, форматов Parquet, Avro, ORC. Помимо Predicate-pushdown существует Projection Pushdown направлено на то, чтобы как можно раньше удалить ненужные столбцы из вычислечний или не извлекать их вообще
— Физическая оптимизация (физический план точно описывает, как нужно делать)Например, логический план просто указывает на то, что необходимо выполнить операцию join, а физический план фиксирует тип соединения (например, ShuffleHashJoin) для этой конкретной операции. Физическим планом часто называют Spark планом, который указывает как логический план будет выполняться на кластере используя разные стратегии физического выполнения и сравнивая их друг с другом посредством модели оценки (cost model). Примером модели оценки может быть сравнение как будут выполняться разные виды Join в зависимости от размера таблицы, насколько большие партиции. Результатом физического плана является RDD трансформации, которые выполняются на каждом узле. Иногда Spark называют компилятором, который принимает запрос через DataFrame, DataSet, SQL API, а потом Spark под капотом компилирует этот запрос в трансформации над RDD
— Генерация кода — создание байт-кода Java для запуска на каждой машине
Pyspark — это API, позволяющее работать с Apache Spark с помощью Python.
Архитектура Spark
Spark Application — приложение, которое состоит из Spark Driver и Spark Executors.
Spark Driver — компонент, который состоит из одного экземпляра в кластере и отвечает за:
— инициирование исполнения программы
— планирует, распределяет и запускает работу Spark Executors
— формирует план запроса, так называемый DAG (Directed Acyclic Graph)
Spark Executor — компонент, который выполняет все распределенные вычисления. Executorов может быть от 0 до n, отвечает за:
— выполнение кода программы, отправленный Spark Driver’ом
— выполняет все распределенные вычисления
— передает информацию о процессе вычислений
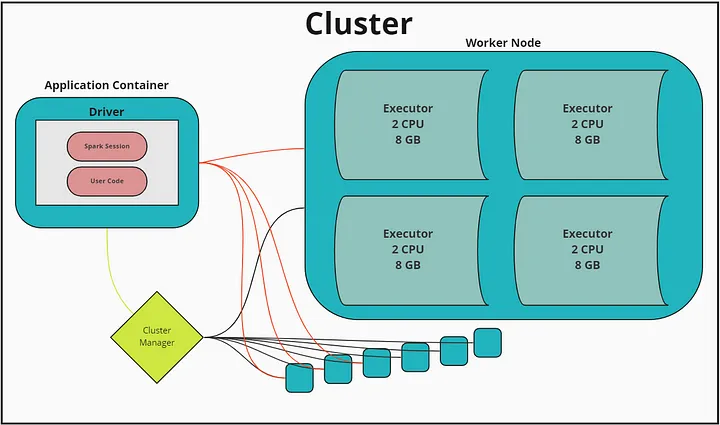
Контейнер — это некий формат пакетирования, упаковки вашего приложения, он позволяет весь ваш код вместе с зависимостями упаковать в некий стандартный формат, чтобы ваше приложение могло запускаться на разных платформах, вычислительных средах.
Spark Session — точка входа для функциональных возможностей Spark:
— позволяет конфигурировать ресурсы, выделяемые для вычислений
— предоставляет доступ ко всем операциям Spark, в том числе и к данным
Spark Session позволяет выделять ресурсы для Spark приложения статически и динамически. При статическом выделяются и резервируются указанное кол-во ресурсов. При динамическом аллоцировании ресурсов они запросятся в нужном размере необходимом для Spark приложения. Помимо этого в Spark есть параметр, который указывает какое кол-во времени ресурсы Spark при динамическом аллоцировании могут простаивать и при достижении этого времени они высвобождаются для решения последующих заданий других приложений.
Архитектура Spark приложения во время исполнения
Spark Application — представляет собой распределенное приложение для получения максимальной производительности для которого необходим кластер, состоящий из нескольких машин под управлением Resource Manager (RM). Наиболее популярными решениями запуска Spark приложения в кластере являются YARN Resource Manager и Kubernetes cluster. Основное отличие запуска Spark в YARN и Kubernetes в том, что развернутые контейнеры YARNом при необходимости могут самостоятельно запрашивать дополнительные ресурсы для вычислений у Resource Manager, в то время как контейнеры в Kubernetes cluster так не умеют.
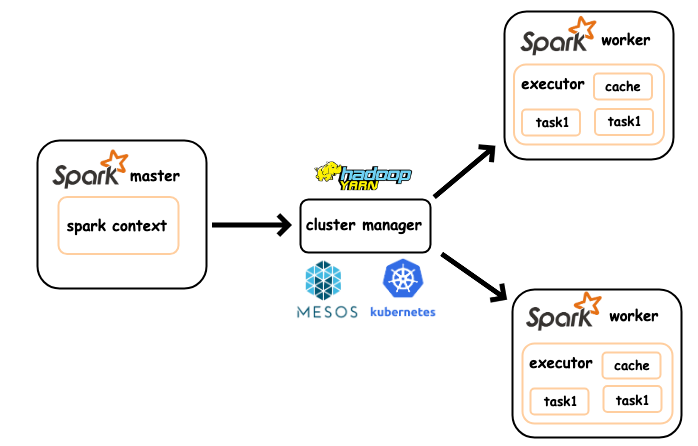
Spark submit — один из подходов запуска Spark приложения в виде консольной утилиты, которая позволяет запускать приложение в кластере. Утилита читает код, подтягивает конфигурацию и отправляет задачу на деплой в кластер, cluster менеджер выделяет ресурсы и разворачивает приложение.
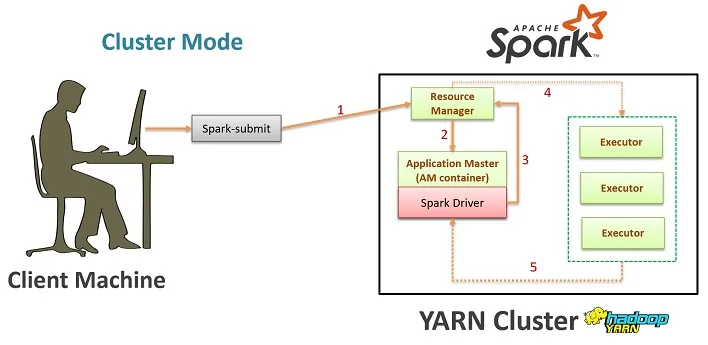
Режимы Deploy Spark приложения
- cluster deploy_mode:
— Driver будет запущен на одной из машин YARN кластера
— Cluster Deploy mode снижает нагрузку на сеть (network latency), где Driver находится в одном контуре с Executor’ами. Вероятность разрыва связи между Driver’ом и Execut’oром в случае с cluster deploy mode’ом намного меньше, так как Driver и Executor находятся в одной сети.
spark-submit —master yarn —deploy_mode clusterОбычно deploy_mode cluster используется в PRODUCTION среде, где для запуска Spark Driver выделяется отдельная машина. В случае запуска приложения в cluster deploy_mode режиме с помощью YARN, запускаемый им Application Master = Spark Driver.
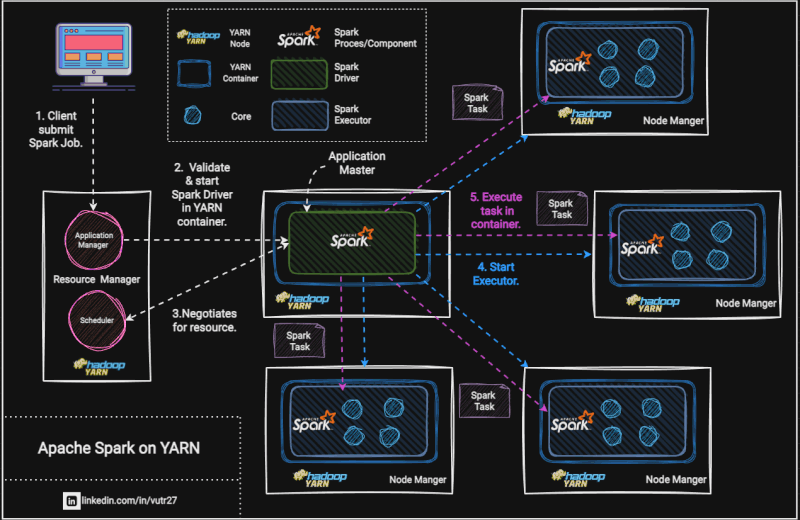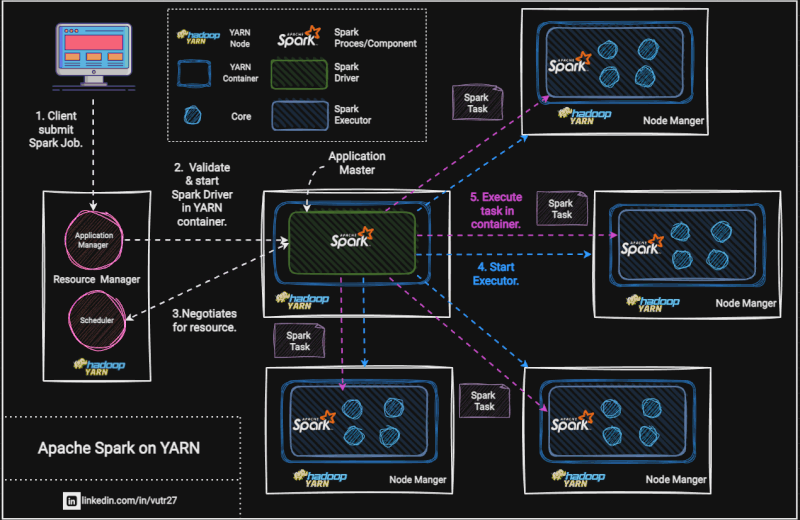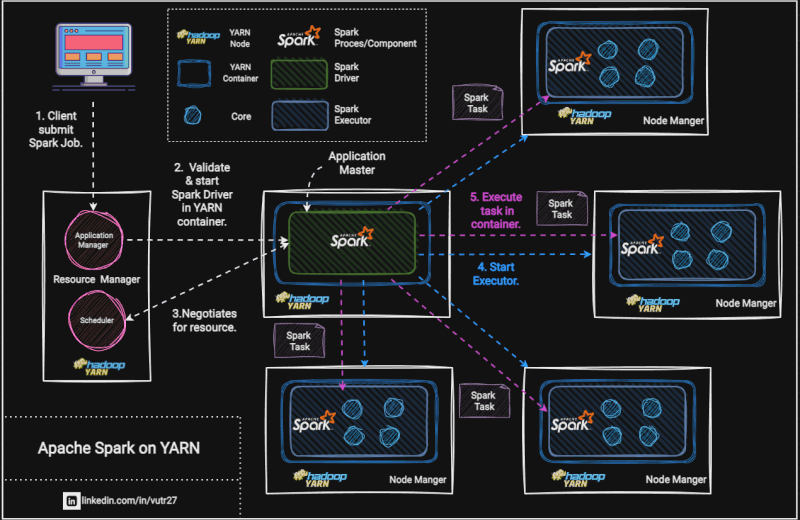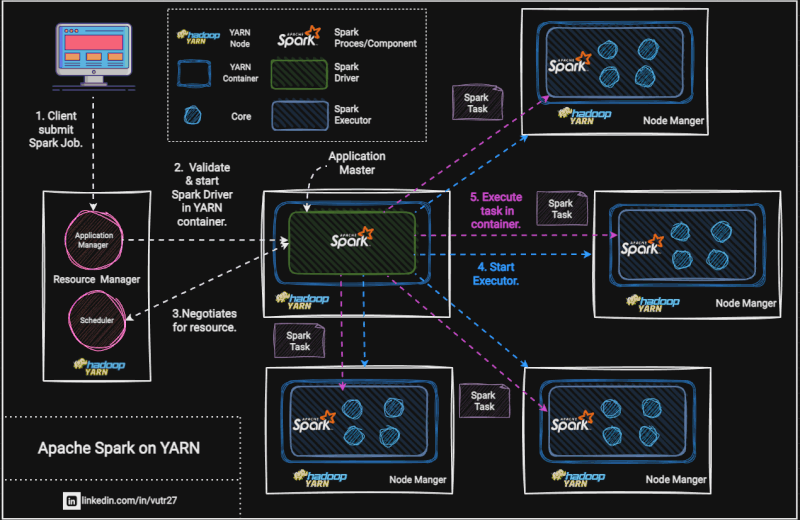
- client deploy_mode:
— Client mode режим используется по умолчанию
— Driver запускается на той же машине откуда и производится spark-submit
— client mode обычно используется для прототипирования, отладки, когда мы хотим увидеть промежуточный результат наших расчетов. Например, работая в JupyterHub’е, сессия запускается всегда с client deploy_mode
spark-submit —master yarn —deploy_mode clientSpark DataFrame и виды операций с ним
Spark Dataframe — наиболее распространенная неизменяемая структура данных в Spark, представляет собой набор типизированных записей, разбитых на блоки. Иными словами — таблица, состоящая из строк и столбцов. Блоки могут обрабатываться на разных вычислительных узлах кластера.
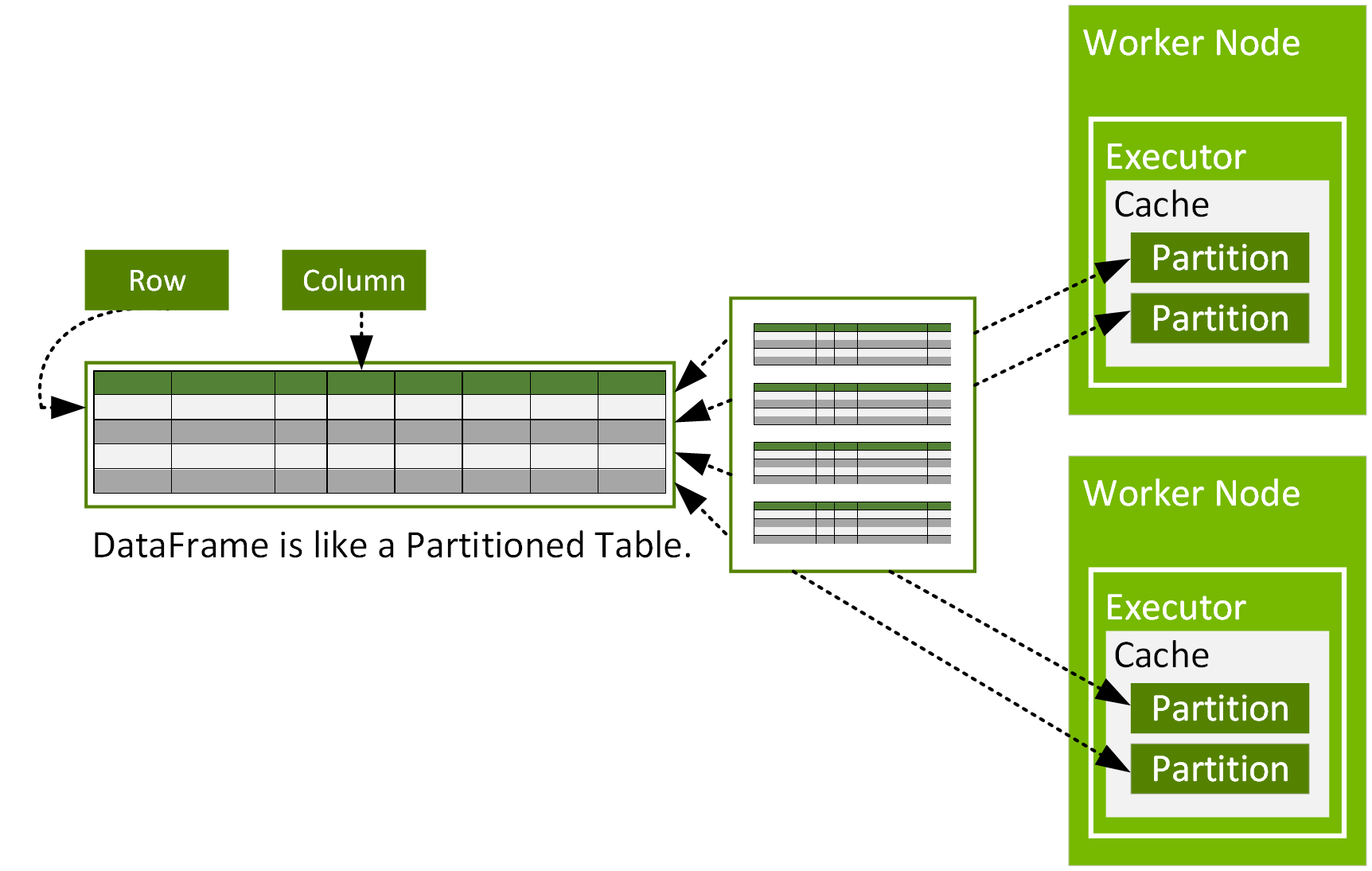
DataFrame поддерживает привычные для работы с данными операторы, такие как:
— select
— filter (фильтрация)
— sort
— withColumn (новые столбцы)
— join (соединение таблиц) и прочие

Spark отчасти напоминает концепт библиотеки Pandas в Python.
Существуют два вида основных операций с Spark Dataframe:
— transformation — изменение существующего Dataframe (возвращает другой dataframe, например, с помощью filter, join)
— action — метод, который поручает Spark вычислить, записать, вернуть результат цепочек преобразований и трансформаций. Такими методами являются, например: count(), show(), write(), save()
Ленивые вычисления — это стратегия вычисления в Spark, при которой запуск расчетов откладывается до того момента, когда понадобится результат. Необходимо это для сокращения объема вычислений за счет оптимизации и исключения вычислений, результат которых не используется. Реализовано это следующим образом, команды преобразования данных запускаются только после вызова action методов в виде одного оптимизированного плана запроса. Оптимизатор строит наиболее эффективный алгоритм, который уже и запускается.
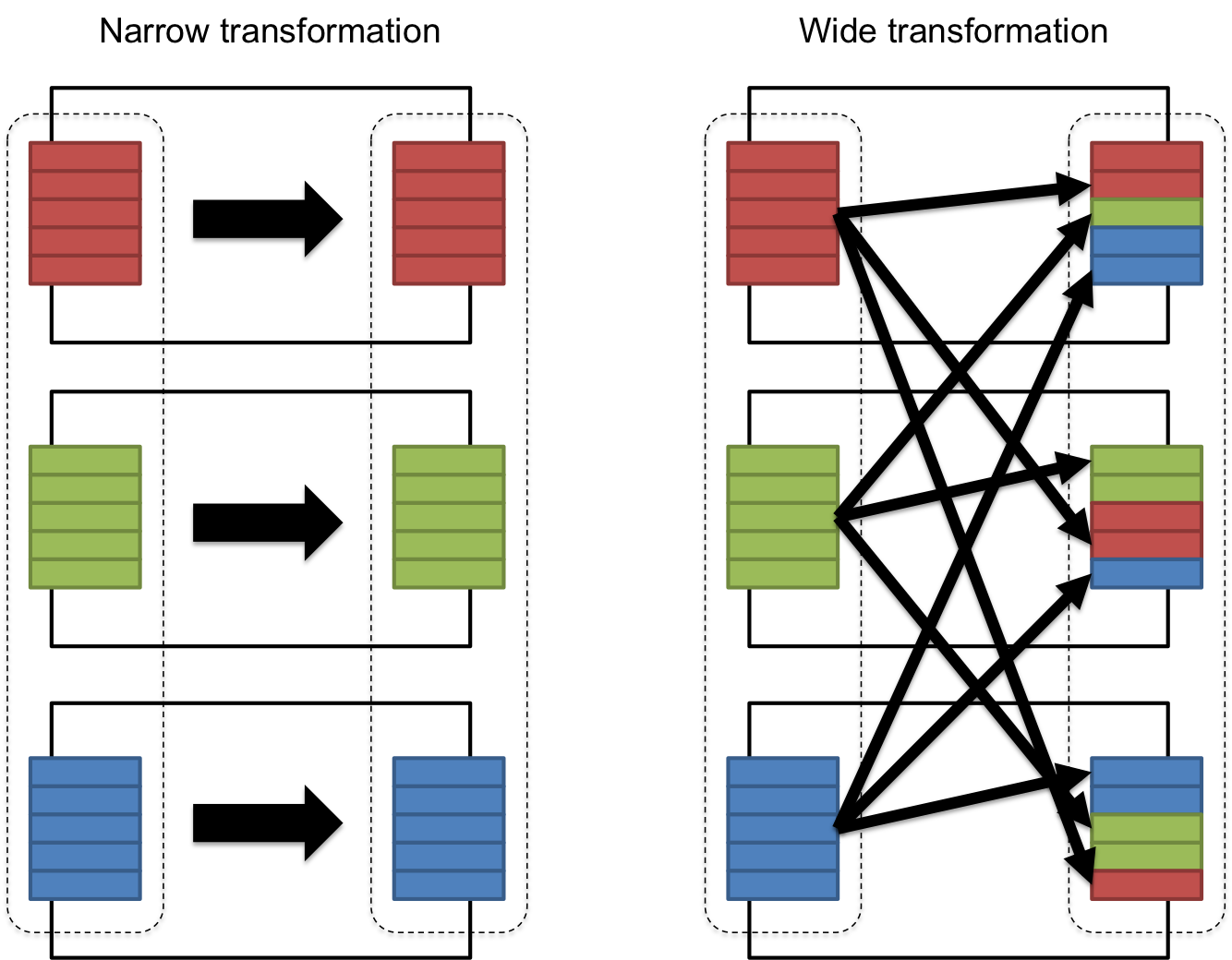
Операции transformation — ленивые операции, они никаких вычислений не запускают. Операции трансформации делятся на:
— Narrow dependency выполняются параллельно над партициями данных (select, filter, drop и не вызывают операции перемешивания (shuffle) данных)
— Wide dependency выполняются на сгруппированных данных, собранных из нескольких партиций (.groupBy(), .join(), orderBy(), distinct(), repartition() вызывают операцию shuffle)
Data shuffle — это процесс перераспределения данных executor’ами для выполнения дальнейшей обработки над сгруппированными данными. Операцию shuffle инициируют широкие (wide) трансформации и прямое использование команды repartition. Результат каждого shuffle записывается на диск.
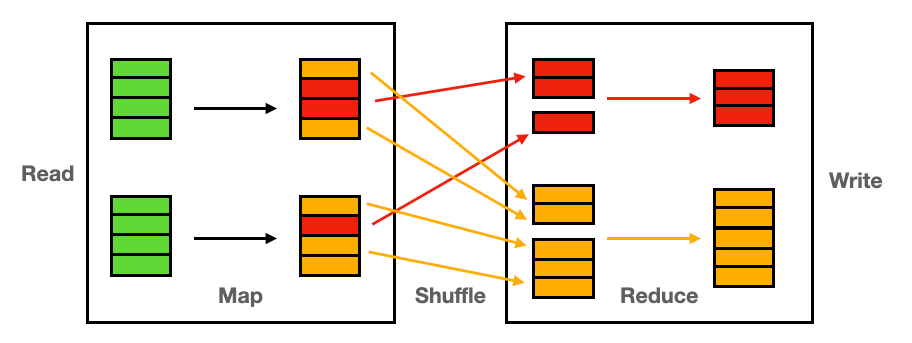
Операции перетасовки данных являются дорогостоящими и часто являются причиной снижения скорости выполнения распределенного приложения из-за:
- Disk IO операции чтения/записи с диска
- Network IO — передачи данных по сети между исполнителями или даже между рабочими узлами в кластере
- Serialization / Deserialization — конвертация Java объектов, представляющие собой обрабатываемые Spark’ом данные в поток байтов (bytes-stream) для передачи их по сети (deserialization соответственно обратный процесс — конвертация bytes-stream в Java объекты).
Операцию shuffle избежать не получится, но можно минимизировать затраты, например, за счет использования фильтрации данных до широких трансформаций, тем самым уменьшая общее кол-во данных к shuffle
Spark Job, Stage, Task
При выполнении action-операций таких как collect(), count() и т. п. инициируется запуск такого компонента как Spark Job.
Spark Job — задача исполнения графа вычислений (DAG), которая разбивается на Spark Stage, а Spark Stage декомпозируется на Spark Task. Каждая action-операция создает отдельный pipeline вычислений, то есть новый Spark Job. Spark Jobы могут работать последовательно и параллельно, в данном случае как выполнять Jobы решает оптимизатор Spark.
Spark Stage — этапы вычислений, на которые разбивается Job, которые зависят друг от друга и используют общий результат перемешивания/перетасовки (shuffle) данных в рамках этапа расчета. Операция перетасовки (shuffle) данных создает новый stage. Stage’ы могут выполняться как параллельно, так и последовательно и делятся на два типа:
— те операции что не вызывают shuffle у Spark могут быть обработаны параллельно. Например, чтение файла.
— последовательно stage’ы выполняются если у них есть функциональная зависимость, stage’ы построен так, что один stage должен получить результат другого stage’а. Например, джоин двух таблиц, чтение данных может произойти параллельно, а вот сам джоин уже будет идти последовательно
Spark Task — наименьшая исполнительная единица в Spark, которая выполняет серию инструкций, например, чтение данных или фильтрацию. Task’и выполняются внутри Executor’ов. Таски — юниты исполнения, которые распределяются между экзекьюторами, каждая таска дается на выполнение одному экзекьютору и выполняется над одной партиции данных. Таким образом один экзекьютор с 16 ядрами (cores) может обрабатывать 16 партиций параллельно.

Партиционирование в Spark
Apache Spark предназначен для обработки больших данных (Big Data), и партиции являются одним из способов это сделать. К плюсам партиций можно отнести:
— быстрый доступ к данным;
— возможность производить операции на меньших датасетах;
Действительно, хранить в оперативной памяти огромный датасет может быть не эффективно, однако его заранее можно разбить на меньшие части, и уже работать с ними. К тому же фильтрационные запросы подразумевают партицирование
К минусам партиций можно отнести:
— наличие большого числа партиций (операции ввода-вывода медленные);
— не решают проблему неравномерности данных (партиции могут быть разного размера)
Существует два вида операции с партиционированием, одни выполняются в оперативной памяти, а другие на диске.
Операции партиционирования в памяти
repartition() — принудительный shuffle данных, на вход подается два аргумента, кол-во партиций и список колонок по которым делается репартиционирование. Это команда делает следующее, одинаковые ключи отправляет на одинаковые executor’ы. С помощью этого метода можно увеличить количество партиций тем самым увеличив уровень параллелизма в кластере Apache Spark. Repartition может хорошо помочь в случае неравномерного распределения или перекоса данных.
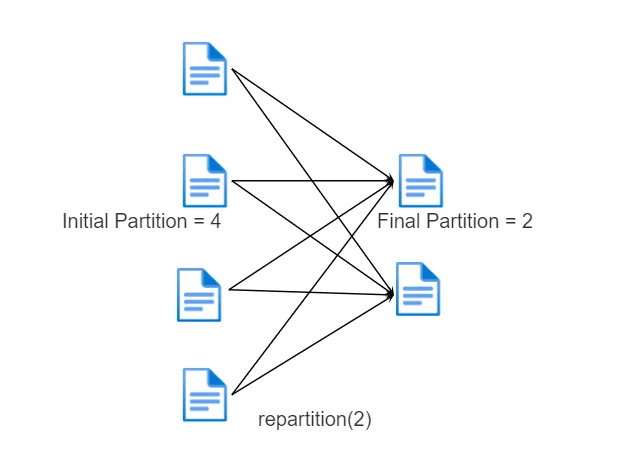
coalesce() — операция оптимизации, которая только уменьшает число партиций наиболее эффективным образом и при этом минимизирует количество перетасовок shuffle. Не может увеличить количество партиций, т. е. повысить уровень параллелизма в кластере Apache Spark. Данная операция может полезна для разделения данных на маленькое кол-во партиций без full shuffle, но есть риск, что данные могут разделиться неравномерным образом.
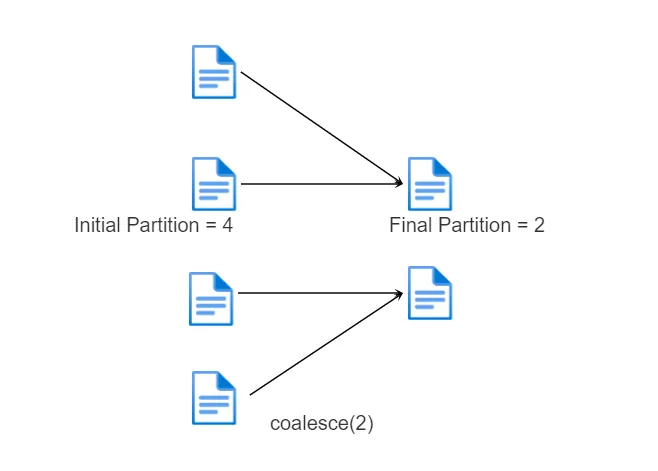
Операция партиционирования на диске
Партиция на диске выполняется с помощью вызова метода partitionBy. При создании партиций на диске они будут сгенерированы на основе уникальных значений столбца(ов), по которому(ым) происходит разбиение. Иными словами, partitionBy работает как groupBy, только вместо групп на диске создаются файлы с партициями.
Разница между операциями в памяти и операциями на диске
partitionBy изменит структуру папок, то есть по сути это аналог партиций Hive, где под каждое значение партиционированной колонки создастся своя папка в HDFS. В то время как repartition() или coalesce() оперируют кол-вом файлов, которые будут записаны в папку HDFS.
Best Practices
- Использовать динамическую аллокацию ресурсов вместо статической. Приложение будет запрашивать ресурсы по мере необходимости и возвращать неиспользуемые ресурсы кластеру. На кластере могут работать тысячи пользователей, при динамической аллокации распоряжение ресурсами происходит более грамотно и можно не переживать за оставленную без присмотра spark-сессию.
Про выделение ресурсов:
— Для Spark Driver’а достаточно 1 ядра (core), 1 гигабайт оперативной памяти
— Если много данных, то нужно выделять много памяти на один Spark Executor, 1-2 ядра и увеличивать кол-во Executor
— Если мало данных, но много операций, трансформаций с данными, то нужно в приоритет ставить кол-во ядер, но меньше выделять памяти
— Параллелизм в Spark определяется по формуле: кол-во экзекьюторов умноженное на кол-во ядер одного экзекьютора, то есть, если у нас spark.executors.cores = 2 и spark.executors.instances = 10, то параллельно 1 экзекьютор может обработать 20 партиций
— Все Executor’ы используют общую оперативную память, то есть она делится между кол-вом ядер этого экзекьютора. Если spark.executors.memory = 8 и spark.executors.cores = 2, то на каждое ядро экзекьютора будет по 4 ГБ памяти
— Существуют операции, которые возвращают данные в Spark Driver collect(), reduce(), count(). Важно понимать, что зачастую на Spark Driver выделяют ограниченное кол-во ресурсов, поэтому данные большого размеры стягивать нельзя. Перечисленные операции используются для получения результата на небольшом по размеру DataFrame. Помимо перечисленных методов данные стягиваются на Spark Driver при broadcast join. При broadcast join датафрейм стягивается на Spark Driver, а дальше его копии рассылаются на каждый Executor. Если датафрейм очень большой, то это будет неэффективно - Следить за кол-вом дорогостоящих операций.
Дорогостоящие операции это:
— чтение исходных данных с диска. Чтобы существенно увеличить производительность в этом пункте необходимо использовать фильтры по полям партицирования таблиц, тем самым мы сократим кол-во перемещений данных по сети между Executor’ами, пользоваться преимуществами столбчатого хранения (ORC/Parquet), а именно считывать только нужные для расчетов поля
— мониторить за вытеснением данных из памяти экзекьютора на локальный диск (spill). Вытеснение данных происходит на локальный диск Executor. После вытеснения данных нужно их снова считывать с диска. Помогает выделить больше памяти, большее кол-во Executor - Обнаружение вытеснения данных с памяти на диск
— Событие вытеснения на диск можно увидеть в логах Executor
— нужно выделять достаточное кол-во памяти на процесс (executor.core) + следить за объемом данных и перекосами. Бывает что данные между экзекьюторами распределяются не равномерно, один экзекьютор читает большую партицию, а остальные маленькие партиции и после завершения работ с маленькими партициями остальные ждут окончания расчета у экзекьютора с большой партицией.
минусы shuffle:
— сериализация/дисериализация данных
— пересылка данных по сети
— возможны вытеснения на диск - Анализировать план запросов с помощью explain.
Оператор возвращает подробную информацию о том, какой план исполнения будет выбран оптимизатором для выполнения скрипта. Запросы нужно читать снизу вверх, смотреть что применились фильтры по партицированию. - Грамотно использовать кэширование данных
Кэширование в Spark — механизм сохранения промежуточных вычислений в памяти экзекьюторов. Экзекьюторы сохраняют обрабатываемые партиции данных в специально выделенную область памяти. Кэширование нужно использовать если один тот же датафрейм используется в алгоритме несколько раз, необходимо это чтобы дважды или более раз не считывать данные с диска. Кэширование происходит с помощью метода cache(). Лучшими практиками является создавать новую переменную под кэшированный датафрейм и хранить в нем только необходимые столбцы, например:
cache_df = df.cache()Для удаления объекта из кэша используется метод unpersist().
- По возможности избегать использоваться UDF
UDF — это реализованные пользователем функции, которые не содержатся во встроенных модулях Spark. В PySpark использование UDF ведет за собой существенную деградацию производительности приложений.
— сериализация/дисериализация данных между JVM и Python интерпретатором
— черный ящик для оптимизатора запросов. Оптимизатор запроса не знает ничего про UDF и не сможет оптимизировать план запроса
— Если нужны UDF, то нужно обратить внимание на Pandas UDF - Broadcast join должен производится только на небольших датафреймах
Основное требование — один из датафреймов должен полностью перемещаться в память и драйвера, и экзекьютора. BroadcastHash join производится по хэшам ключей. Для построения HashMap, которая будет разослана на все экзекьюторы, Spark сначала вытянет все данные на драйвер. Для определения размера датафрейма Spark опирается на статистику по таблице, хранящуюся в том же Hive, а она может быть некорректной, что приводит к переполнению ресурсов Spark Driver - При записи в HDFS не нужно создавать много маленьких файлов
При проведении трансформаций spark по умолчанию создает 200 партиций. При записи на диск каждая партиция будет записана в отдельный файлик. Особенности архитектуры HDFS, каждый блок занимает оперативную память на NameNode, а она лимитированная. Лучшими практиками в данной ситуации будет:
— кол-во файлов не превышает параллелизм при чтении
— размер файла меньше размера блока на Data Node и все файлы примерно одинакового размера