
Apache Kafka

Message broker — это тип построения архитектуры, при котором элементы системы «общаются» друг с другом с помощью посредника. Данная архитектура нужна чтобы доставлять сообщения из пункта А в пункт Б, причем мы предполагаем, что эти сообщения бесконечны. Таким образом потоковая передача данных отличается от пакетной (пакетная рано или поздно завершится, имеет границы и ее можно разделить на эти границы). Message broker’ы активно используются в микросервисной архитектуре, где используется событийно-ориентированный подход. Преимуществами микросервиса над монолитным приложением являются низкая связь сервисов друг с другом, устойчивость приложений к сбоям за счет изоляции поставщиков (producer) и потребителей (consumer).
Типы Message broker’ов:
— point-to-point, брокеры которые работают на принципе доставки сообщения в строгой последовательности в виде очереди, где одна система пишет сообщение по принципу first in/ first out, другая очередь эти сообщения вычитывает. Примеры таких брокеров: ZeroMQ, nanomsg, Java Message service (JMS)
— publish / subscribe Есть некий producer, который публикует свои сообщения, есть так называемые потребители (consumer), которые эти сообщения получают именно по подписке. Строгая последовательность доставки сообщений не гарантируется. Системы с таким типом являются более масштабируемыми. Примеры таких брокеров: Celery, ActiveMQ, Apache Kafka, IBM MQ
В терминалогии потоковых данных событие генерируется 1 раз инициатором, а затем обрабатываются различными потребителями. Инициаторов может быть много, кто передает эти данные, также и потребителей может быть много.
Назначение Message broker:
— интеграция систем, написанные на разных языках программирования и протоколах
— гарантия надежного хранения
— гарантированная доставка
— масштабирование (как источников, так и потребителей)
— преобразование сообщений
Apache Kafka — это распределенная и легко масштабируемая система обмена сообщениями, написанная на Java и Scala, с высокой пропускной способностью, которая может в режиме реального времени обрабатывать большие объемы данных. Kafka появилась из-за необходимости компании LinkedIn эффективно перемещать огромные количества сообщений — до нескольких терабайт в час.
Верхнеуровнево Kafka состоит из:
— Broker
— ZooKeeper или KRaft
— Consumer
— Producer
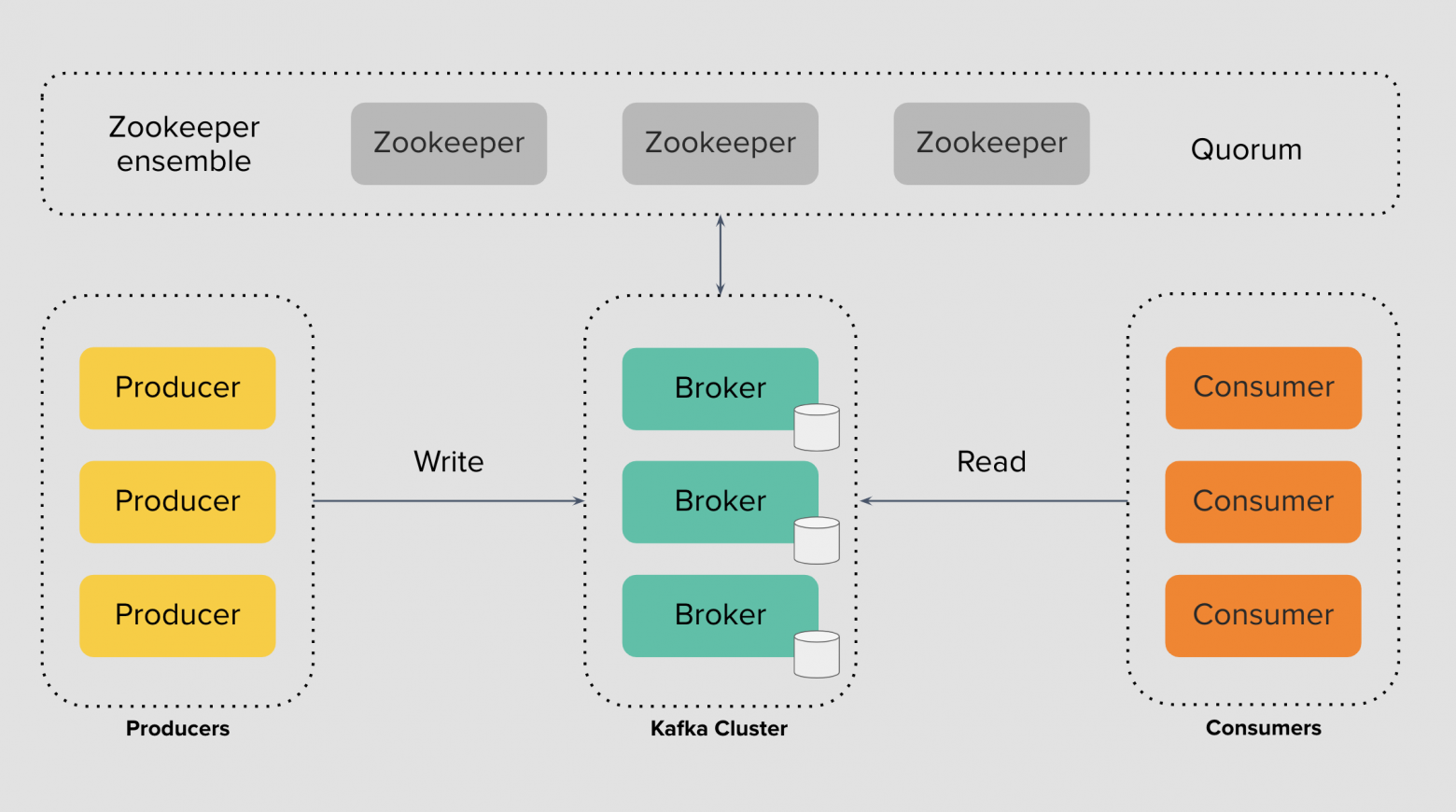
Broker — это серверное программное обеспечение с доступом к своему локальному диску, в которое producer’ы записывают данные, а consumer’ы читают данные, Broker эти данные аккумулирует и правильно сохраняет. Apache Kafka кластер состоит из множества Broker’ов, которые объединены в одну сеть.
ZooKeeper — это распределенное файловой хранилище необходимое для достижения согласованного состояния и синхронизации Broker’ов. Благодаря ZooKeeper мы можем управлять кластером Kafka, добавлять новых пользователей, создавать топики, задавать им настройки, обнаруживать сбои и восстанавливать работу кластера, хранить конфигурацию и секреты, авторизационные данные и ограничения или Access Control Lists при работе консумеров и продюсеров с брокерами.
Consumer — это приложение, которое имеет модуль Kafka, с помощью которого оно может прочитать сообщение. Приложение-консумер подписывается на события и получает данные в ответ.
Producer — это приложение, которое имеет модуль Kafka, с помощью которого оно может записать событие (сообщение) в кластер Kafka. Кластер сохраняет эти события и возвращает подтверждение о записи или acknowledgement.
Брокеры
Чтобы Broker’ы знали куда нужно отправить сообщение producer’а и какие consumer’ы могут читать эти сообщения существует такое понятие как Topic
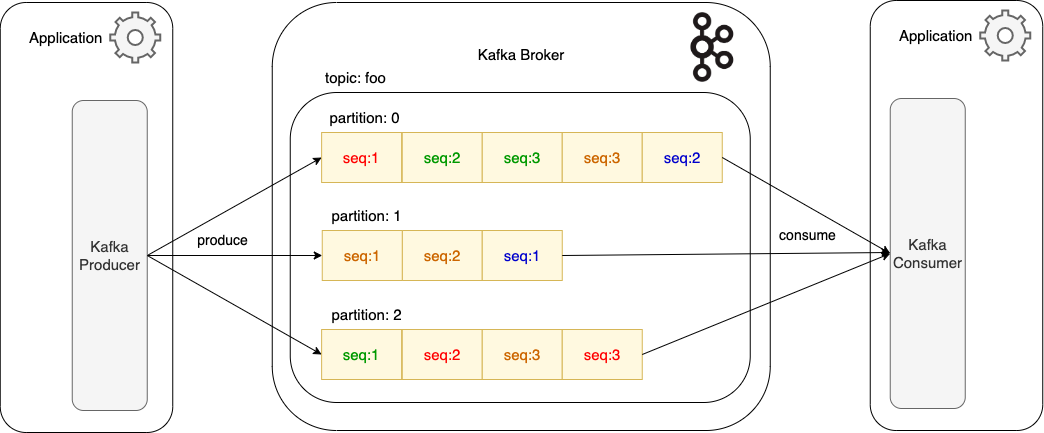
Topic — это базовая, основная сущность Apache Kafka, логическое разделение коллекции связанных сообщений на группы, последовательность событий. Топик удобно представить в виде лога, в который постоянно добавляются новые данные в конец, тем самым не разрушается цепочка старых событий. Отличие топика Kafka от остальных топиков очередей тем что данные в топике Kafka нельзя удалить используя Consumer или Producer.
Topic состоит из партиций, которых может быть одна или несколько. Партиции — это главный механизм масштабирования и отказоустойчивости. 1 партиция — это 1 копия данных. Партиция может находится как на одном брокере, так и на нескольких. Сколько нужно партиций зависит от того насколько много consumer’ов читает топик и насколько часто они читают из этого топика. Если довольно часто, то в идеале для каждого consumer’а иметь свою отдельную партицию.
Сами партиции физически представлены на дисках в виде сегментов. Сегмент — это отдельный файл, хранящийся на диске брокера. Файлы можно создавать, ротировать с одного брокера на другой, удалять согласно настройке устаревания. Число сегментов может варьироваться в зависимости от интенсивности записи и настроек размера сегмента. При превышении размера сегмента создается новый.
Хранение данных
Семантически и физически сообщения внутри сегмента не могут быть удалены, они иммутабельны. Всё, что мы можем — указать, как долго Kafka-брокер будет хранить события через настройку политики устаревания данных retention policy и указать cleanup policy, когда наступает некое событие для очистки данных.
Retention policy правила, которые позволяют избавляться от устаревших данных на основании времени. При достижении порога данные помечаются на удаление. Существуют следующие опции настройки:
— по милисекундам log.retention.ms
— по минутам log.retention.minutes
— по часам log.retention.hours
Помимо этого существует size based подход, где оценивается размер сегмента, который может хранить топик:
— log.segment.bytes
Cleanup policy состоит из:
— Delete (по умолчанию). Помечает на удаление segment при устаревании / превышении размера
— Compact. Оставляет только последние сообщения для каждого ключа (message key)
— Delete и Compact. Производится compaction и удаление согласно retention policy
Репликация данных
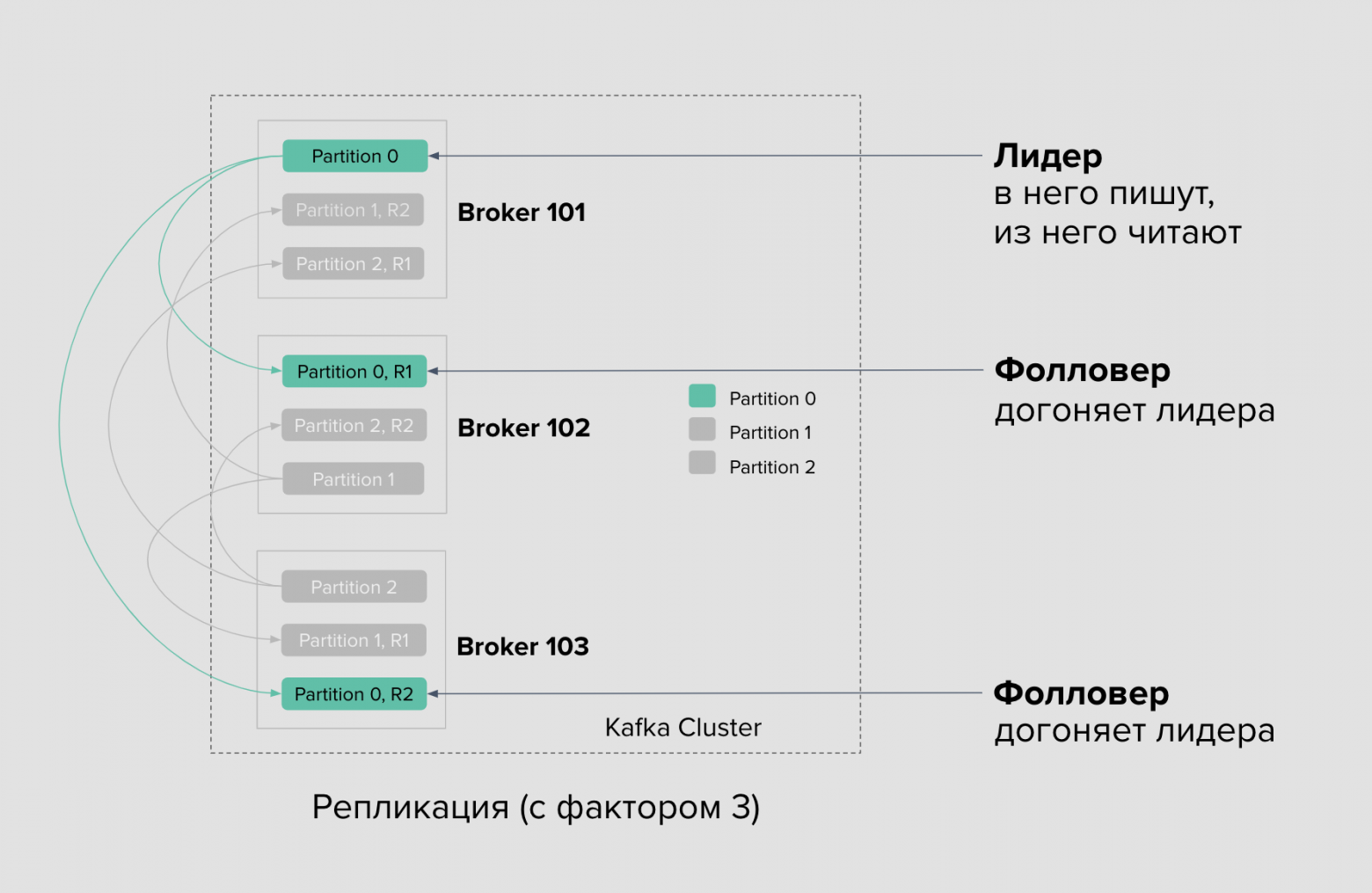
Для обеспечения отказоустойчивости и сохранности данных существует механизм репликации между брокерами, который имплементируется на уровне партиций:
— У каждой партиции есть настраиваемое число реплик
— Одна из этих реплик называется партицией-лидером, которая принимает все запросы на запись/чтение данных. Все остальные являются партициями-фолловерами
— Записанные данные в партицию лидера автоматически реплицируются фолловерами внутри кластера Kafka. Фолловеры подключаются к лидеру, читают данные и асихронно сохраняют к себе на диск
— Роли лидеров и фолловеров не статичны. В случае выхода из строя брокера с лидирующими партициями, роль лидера достанется одной из реплик фолловеров, а консумеры и продюсеры получат обновление о необходимости переподключиться к брокерам с новыми лидерами партиций
— Начиная с версии Kafka 2.4 консумеры могут читать с партиций фолловеров. Это полезно для сокращения задержек при обращении к ближайшему брокеру в одной зоне доступности. Однако, из-за асинхронной работы репликации, взамен вы получаете от фолловеров менее актуальные данные, чем они есть в лидерской партиции
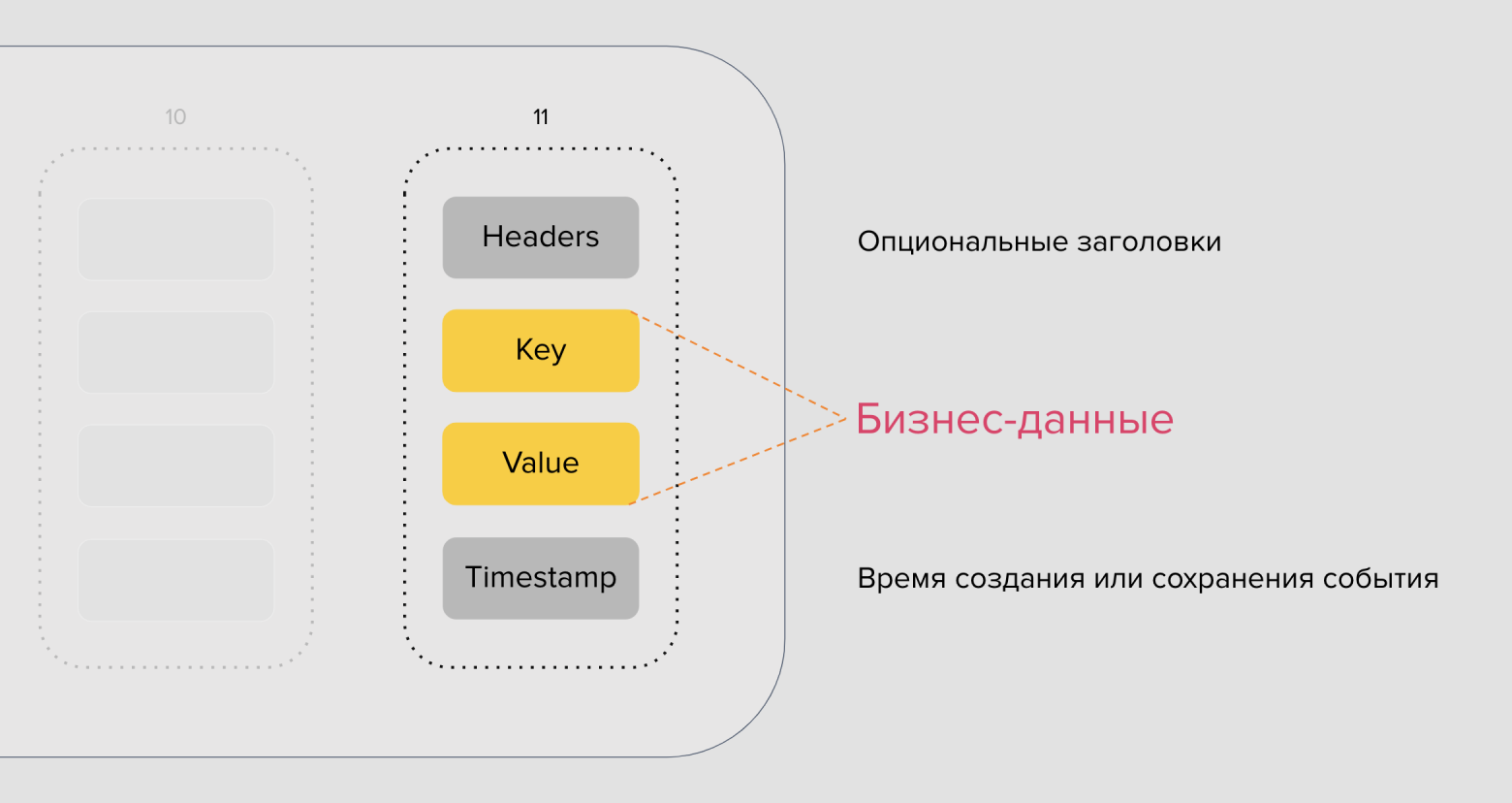
Что из себя представляет сообщение Kafka
Каждое событие — это пара ключ-значение. Ключ партицирования может быть любой: числовой, строковый, объект или вовсе пустой. Значение тоже может быть любым — числом, строкой или объектом в своей предметной области, который вы можете как-то сериализовать (JSON, Protobuf, …) и хранить. В сообщении продюсер может указать время, либо за него это сделает брокер в момент приёма сообщения. Заголовки выглядят как в HTTP-протоколе — это строковые пары ключ-значение. В них не следует хранить сами данные, но они могут использоваться для передачи метаданных.
Запись данных producer’ом
Чтобы producer смог отправить данные в Kafka кластер ему необходимо знать IP адреса всех брокеров и название топика. Перед тем как producer пойдет записывать данные он опросит брокер из своего пула и уточнит какая его партиция является лидером в топике и какое местоположение этой партиции в файловой системе. Запись осуществляется только в партицию-лидер.
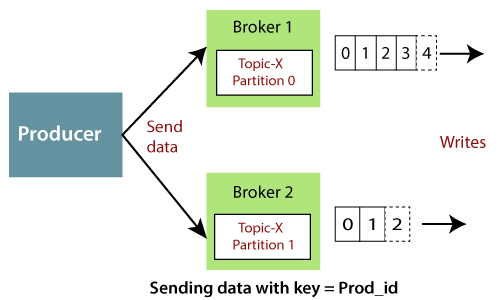
Продюсер определяет стратегию партицирования, она может быть как по ключу сообщения, по очереди (round-robin), так и кастомная, реализованная на стороне продюсера. По ключу сообщения одного и того же идентификатора сохраняются в одну партицию. Примером такого ключа может быть номер карты, ID клиента и т. д. Например, ключ со значением Prod_id_1 всегда будет сохраняться в партицию 0, а со значением Prod_id_2 будет сохраняться в партицию 1, то есть данные не будут распределены по всем имеющимся партициям.
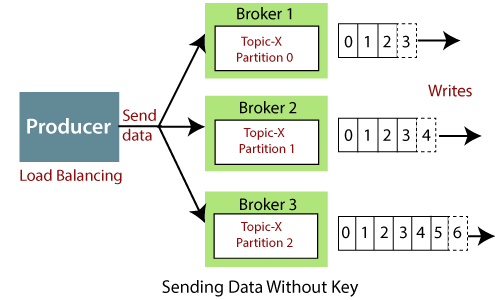
При round-robin сообщения попадают в партиции по очереди, такая стратегия хорошо работает когда нужно равномерно распределить сообщения между всеми существующими партициями и очередность не играет роли.
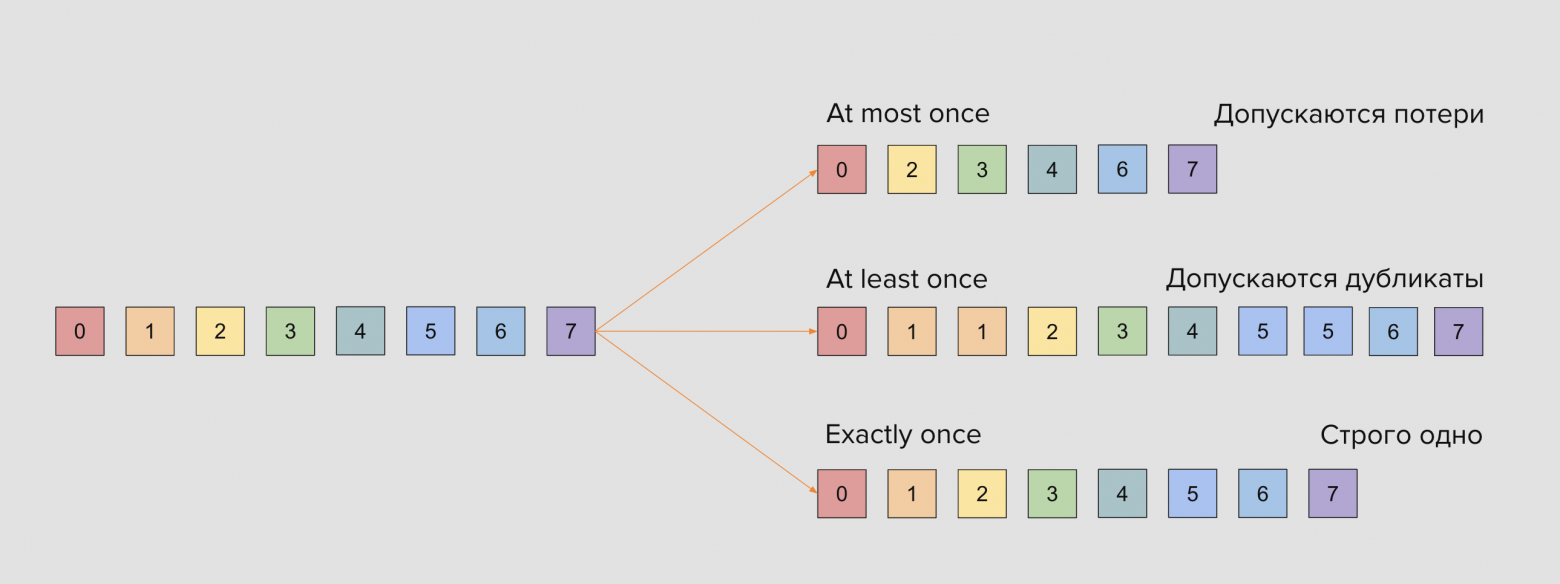
Семантики доставки сообщений
В очередях есть выбор между скоростью доставки и расходами на надежность доставки.
— at-most once — при доставке сообщений устраивают потери сообщений, но не их дубликаты. Это самая слабая гарантия, которую реализуют брокерами очередей
— at-least once — не хотим терять сообщения, но нас устраивают дубликаты
— exactly-once — хотим доставить одно и только одно сообщение ничего не теряя и ничего не дублируя. Высокая надёжность данной семантики означает большие задержки
Надежность доставки
Надежность доставки продюсером данных в брокер осуществляется с помощью возвращения подтверждения записи данных продюсеру в партиции регулируется параметром acks.
— При значении acks=0 продюсер не получает подтверждение от брокера, что запись произошла успешно. Данная политика влечет за собой риски потери данных
— При значении acks=1 продюсер будет ожидать получения ответа об успешной записи данных от лидера партиции
— При значении acks=all продюсер ожидает подтверждения и от лидера партиции, и от фолловеров партиции. Данный вариант является самым надежным и самым трудозатратным, так как требует больше накладных расходов: мало того, чтобы нужно сохранить на диск, так ещё и дождаться, пока фолловеры отреплицируют сообщения и сохранят их к себе на диск. При включенной опции enable.idempotence сообщениям проставляется PID (идентификатор продюсера) и увеличивающийся sequence number. Таким образом обеспечивается транзакционность и в случае сбоя в сети при попытке доставить сообщение повторно сообщения с одинаковым PID будут отброшены со стороны брокера.
Чтение данных consumer’ом
Консумеры читают данные синхронно или асинхронно из лидерской партиции — это позволяет достичь консистентности при работе с данными. Информация в партиции читается слева-направо. Консумеров, читающих сообщения из топика, может быть несколько, причем читать они могут с разных позиций партиции, тем самым не мешая друг другу. Также нет какой-то привязки к чтению по времени, в зависимости от задачи консумеры могут читать спустя дни, недели, месяцы или несколько раз через какое-то время. Сама Kafka (в данном случае брокер) не следит за тем какое сообщение будет читать consumer и когда ему приходить за этими сообщениями. Consumerы сами должны ходить в Kafka и читать оттуда сообщения, сами должны говорить Kafka какие сообщения им выдать
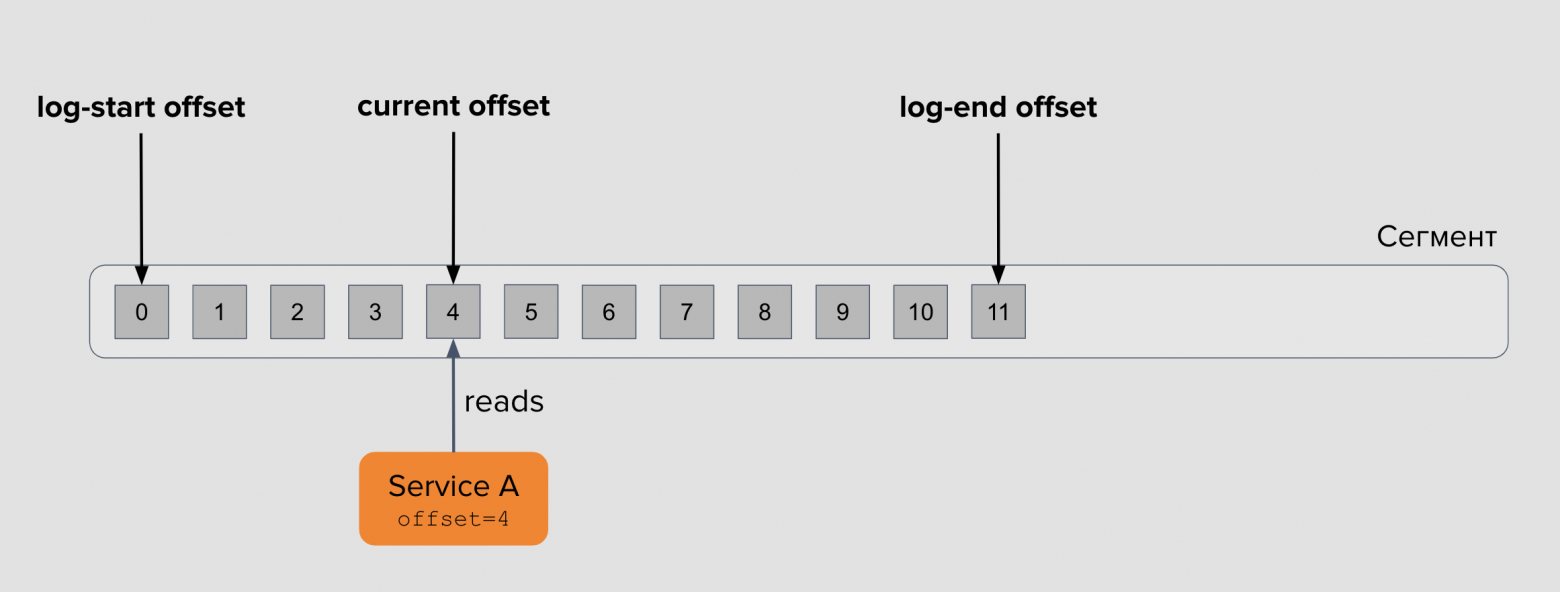
Offset — это позиция сообщения в очереди Kafka. Начальная позиция в сообщении называется log-start offset. Позиция сообщения, записанного последним — log-end offset. Позиция консумера сейчас — current offset. Расстояние между конечным оффсетом и текущим оффсетом консумера называют лагом — это первое, за чем стоит следить в своих приложениях. Допустимый лаг для каждого приложения свой, это тесно связано с бизнес-логикой и требованиями к работе системы.
Consumer при чтении умеет запоминать на каком offset он остановился. Сохранение события фиксации позиции сообщения происходит в специальный Kafka топик _consumer_offset. Под событием фиксации понимается так называемые commits, их может быть два:
— auto commit (по умолчанию). Он вычитывает кол-во offset (батч оффсетов) и потом фиксирует, какое кол-во offsetов он прочитал.
— user commit. Можно организовать свою логику фиксирования коммитов, например, прочитал 1 offset, зафиксировал коммит. Минус такого подхода — снижение производительности
Как обеспечивается то, что консумеры читают разные данные, разные партиции, а не одни и теже:
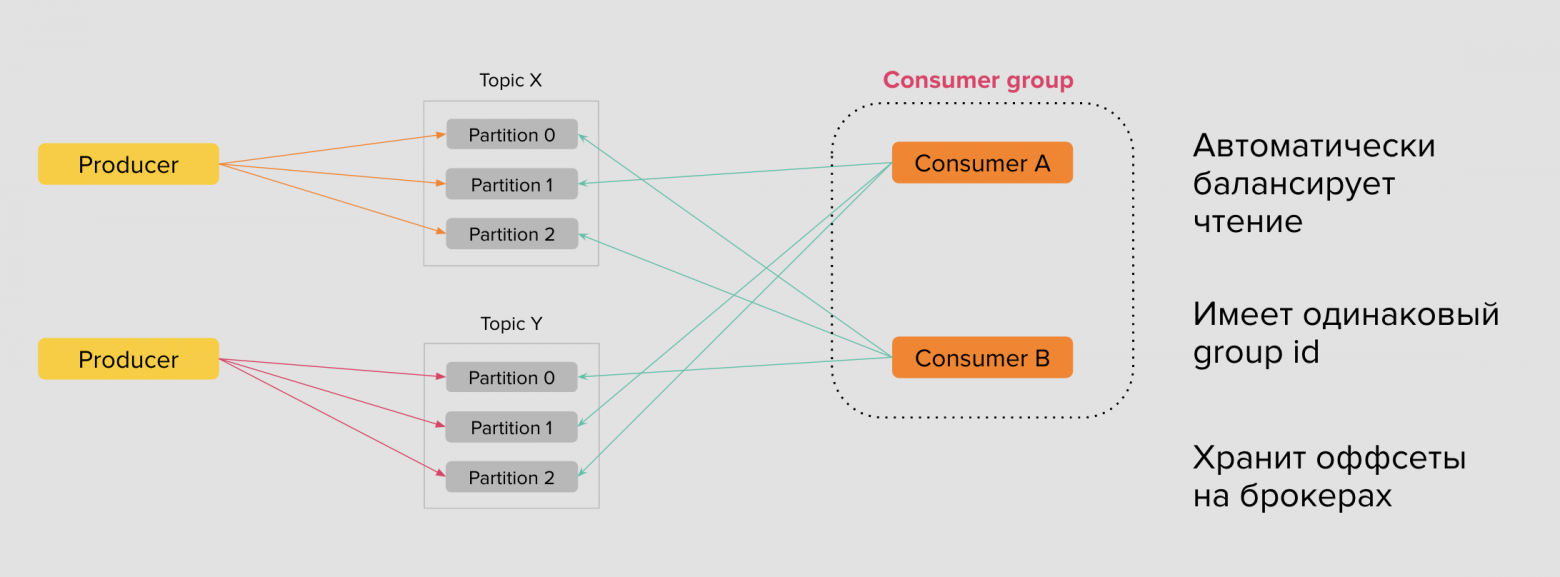
— Для этого есть такое понятие как консумер группы (consumer groups) — это множество консумеров объединившихся в один кластер.
— Каждый консумер в группе будет читать разные сообщения. Каждый консумер пойдет в свою партицию и будет читать именно ее. Читать будет с того места где он остановился прошлый раз
— Kafka сохраняет на своей стороне текущий оффсет по каждой партиции топиков, которые входят в состав консумер-группы. Консумер в группе, после обработки прочитанных сообщений отправляет запрос на сохранение оффсета — или коммитит свой оффсет
— Распределение партиций между консумерами в пределах одной группы выполняется автоматически на стороне брокеров. Kafka старается честно распределять партиции между консумер-группами, насколько это возможно.
— Консумер группы создаются для решения разных кейсов. То есть данные могут быть одни и те же, но пользователи и задачи решаемые этими пользователями будут разные. Например, один консумер использует логи авторизаций пользователей для нужд администраторов, а другая консумер группа в виде маркетологов нужно смотреть кол-во авторизовавшихся пользователей на странице.
— Каждая такая группа имеет свой идентификатор, что позволяет регистрироваться на брокерах Kafka. Пространство имён консумер-групп глобально, а значит их имена в кластере Kafka уникальны.
Ребалансировка консумер-групп
При добавлении новых потребителей топика происходит ребалансировка консумер-группы. Процесс ребалансировки заставляет все консумеры прекратить чтение и дождаться полной синхронизации участников, чтобы обрести новые партиции для чтения. Как только группа стала стабильной, а её участники получили партиции, консумеры в ней начинают чтение. Поскольку группа новая и раньше не существовала, то консумер выбирает позицию чтения оффсета: с самого начала earliest или же с конца latest. Топик мог существовать несколько месяцев, а консумер появился совсем недавно. В таком случае важно решить: читать ли все сообщения или же достаточно читать с конца самые последние, пропустив историю. Выбор между двумя опциями зависит от бизнес-логики протекающих внутри топика событий.
Для того чтобы понимать какие из участников группы активны и работают, а какие уже нет, каждый консумер группы в равные промежутки времени отправляет Heartbeat-сообщение. Временное значение настраивается программой-консумером перед запуском. Также консумер объявляет время жизни сессии — если за это время он не смог отправить ни одно из Heartbeat-сообщений брокеру, то покидает группу. Брокер, в свою очередь, не получив ни одно из Heartbeat-сообщений консумеров, запускает процесс ребалансировки консумеров в группе.
Процесс ребалансировки проходит достаточно болезненно для больших консумер-групп с множеством топиков. Поэтому разработчикам программ-консумеров обычно рекомендуют использовать по одной консумер-группе на топик. Также полезно держать число потребителей не слишком большим, чтобы не запускать ребалансировку много раз, но и не слишком маленьким, чтобы сохранять производительность и надёжность при чтении. Значения интервала Heartbeat и время жизни сессии следует устанавливать так, чтобы Heartbeat-интервал был в три-четыре раза меньше session timeout. Сами значения нужно выбирать не слишком большими, чтобы не увеличивать время до обнаружения «выпавшего» консумера из группы, но и не слишком маленьким, чтобы в случае малейших сетевых проблем, группа не уходила в ребалансировку.
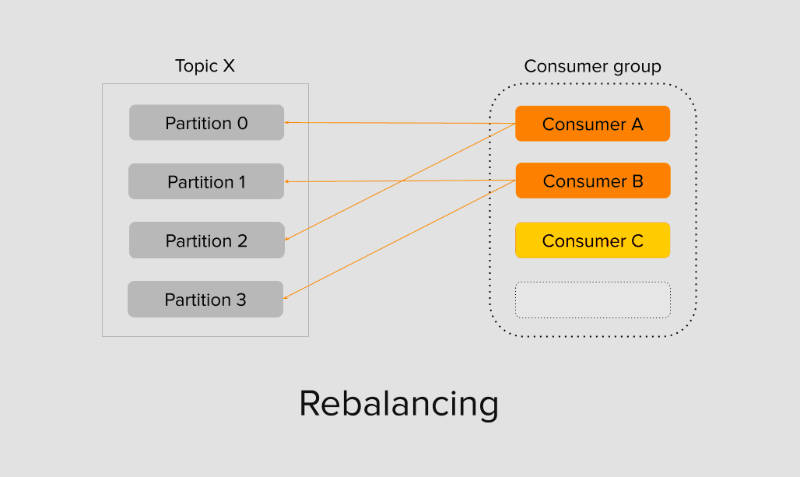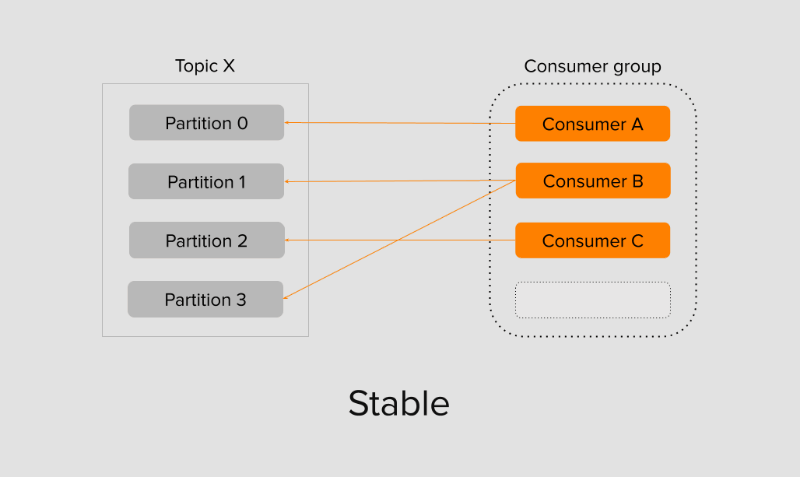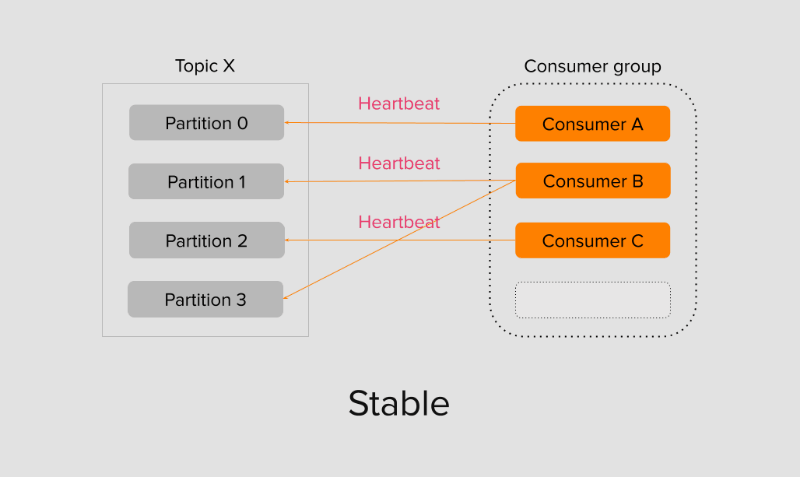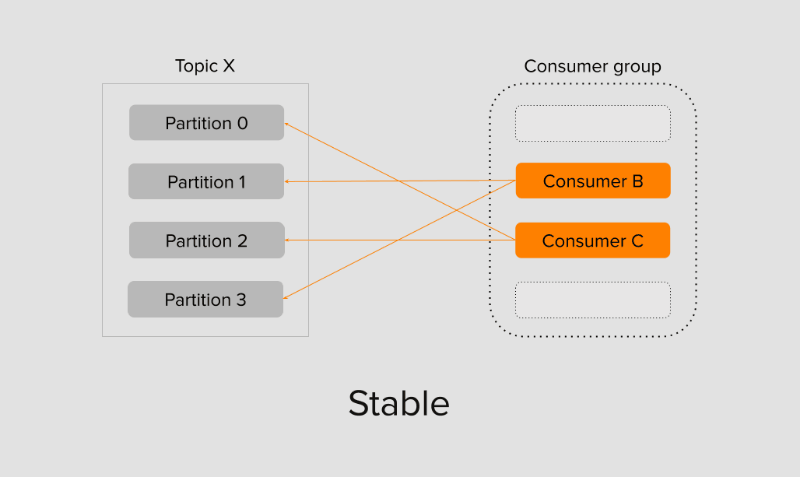
Ещё один гипотетический сценарий: партиций в топике 4, а консумеров в группе 5. В этом случае группа будет стабилизирована, однако участники, которым не достанется ни одна из партиций, будут бездействовать. Такое происходит потому, что с одной партицией в группе может работать только один консумер, а два и более консумеров не могут читать из одной партиции в группе. Отсюда возникает следующая базовая рекомендация: устанавливайте достаточное число партиций на старте, чтобы вы могли горизонтально масштабировать ваше приложение.
Бонус:
Неплохой ролик о том какие проблемы решает Kafka, какие его преимущества в сравнении с другими брокерами сообщений и многое другое. В ролике отличная анимация и демонстрация работы основных компонентов Kafka