
Apache Hadoop

{kind=link}
Hadoop — проект фонда Apache Software Foundation, созданный в 2005 году и предназначенный для эффективного хранения и обработки больших наборов данных объемом от сотен гигабайт до петабайтов.
Под словом Hadoop может подразумеваться:
— Несколько сервисов, составляющих ядро Hadoop (YARN, HDFS, MapReduce)
— Вся экосистема сервисов Hadoop
— Кластер под управлением Hadoop
Предпосылки создания Hadoop
Из-за значительного роста обрабатываемых данных (терабайты, петабайты) действующие на тот момент системы уже эффективно не справлялись с обработкой такого потока данных. Помимо этого необходимо было где-то разместить (хранить) такое кол-во данных без потери информации, с сохранением ее постоянной доступности. Так появилась потребность в распределенном хранилище данных. Чтобы обеспечить высокую пропускную способность большого кол-ва данных необходимо было распараллелить вычисления эффективным и отказоустойчивым способом на кластере машин. Кроме того появление новых источников нетабличных данных как, например, логи, содержимое веб-страниц, тоже являлось предпоссылкой создания нового решения обработки и хранения данных, так как сложно решить данные задачи посредством обычных реляционных БД. Одним из основных достоинств Hadoop является то, что он проектировался так, чтобы стабильно работал на кластерах серверов не премиального класса.
В то время при разработке приложений для распределенной обработки данных возникали следующие проблемы:
1) В кластере серверов сложно определить какой сервер является лидером, то есть сервер, который управляет всеми остальными
2) Проблема координации кластера
3) Отсутствие достаточной отказоустойчивости. При реализации сценария выхода из строя одной ноды не было четкого плана действий, механизмов у кластера для автоматического восстановления работы системы или продолжения функционирования системы без отказавших нод
4) Проблема консистентности данных. Сложность разработки приложения с распределенной обработкой
5) Отсутствие инструмента по управлению приоритетов обработки данных, по управлению вычислительными ресурсами кластера (CPU, RAM, HDD) в том числе если ресурсы запрашивают сразу несколько приложений
Поэтому чтобы решить все вышеперечисленные проблемы был создан Hadoop.
Ядро Hadoop 2.0
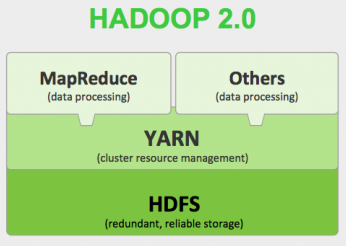
MapReduce — это фреймворк для обработки наборов данных с помощью параллельного распределенного алгоритма
HDFS — файловая система, предназначенная для хранения файлов больших размеров, поблочно распределенных между узлами вычислительного кластера
YARN — модуль, отвечающий за управление ресурсами кластеров и планирование заданий
Others data processing — остальные фреймворки по процессингу данных, например, Apache Spark, Apache Kafka, которые позволяют обрабатывать данные с помощью новых оптимизаций, что приводит к значительному приросту производительности по сравнению с MapReduce. Помимо этого другие фреймворки могут работать с разными видами нагрузок данных, например, streaming, циклические алгоритмы, в то время как MapReduce предназначен для batch обработки.
Apache ZooKeeper
Apache ZooKeeper — инструмент, который следит за синхронизацией, координацией, состоянием всего кластера распределенных приложений. ZooKeeper позволяет Big Data разработчику сосредоточиться над логикой своего приложения, вся координация сервисов ложится на плечи ZooKeeper. Apache ZooKeeper представляет из себя консистентную файловую систему небольшого размера.
Архитектура HDFS
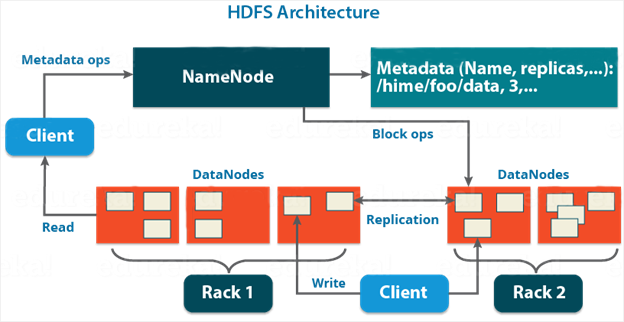
HDFS (Hadoop Distributed File System) — это распределенная append-only файловая система для хранения файлов больших размеров, поблочно распределенной по узлам вычислительного кластера. Любая файловая система состоит из иерархии каталогов с вложенными в них подкаталогами и файлами.
NameNode — это отдельный сервер, единственный в кластере для управления пространством имен файловой системы, хранящий дерево файлов, а также мета-данные файлов и каталогов. Данный сервер отвечает за открытие и закрытие файлов, создание и удаление каталогов, управление доступом со стороны внешних клиентов и соотвествие между файлами и блоками, которые реплицируются на остальные узлы данных. Сервер NameNode раскрывает расположение блоков данных на машинах кластера.
Secondary NameNode — отдельный сервер, единственный в кластере, который копирует образ HDFS (fsimage) и лог транзакционных операций (чтения, записи, удаления и т. д.) с файловыми блоками, применяет изменения, накопленные в логе к образу HDFS, а также записывает его на узел NameNode. Secondary NameNode необходим для быстрого ручного восстановления NameNode в случае его выхода из строя.
fsimage — образ файловой системы HDFS, в котором хранятся логи операций, которые происходили на NameNode. Так как вычитывать все операции логов над блоками за глубокую историю HDFS неэффективно, значит нужно объединять (merge) предыдущую версию логов операций с файловой системой с новоприбывшей пачкой логов. Данный процесс и происходит в fsimage, где он периодически обновляется новыми логами. В случае выхода из строя NameNode и его успешного восстановления, то чтобы ему вернуться к актуальному состоянию файловой системы HDFS происходит чтение fsimage с последнего объединения логов в Secondary NameNode.
DataNodes — множество серверов в кластере, отвечающие за файловые операции, хранение и работу с блоками данных. Основная необходимость DataNode — это чтение и запись данных, выполнение команд от NameNode по созданию, удалению и репликации блоков, а также периодическую отправку сообщений о состоянии обработки запросов на чтение и запись, поступающих от клиентов файловой системы HDFS. Приложению работающему с Apache Hadoop не достаточно иметь доступ только к NameNode, она должна иметь доступ к каждой DataNode.
В HDFS есть 3 места, где могут храниться его настройки:
— глобальные настройки для всего HDFS кластера, это те настройки, которые применяются по умолчанию, если мы не указали что-то отличное. Одной из таких настроек — это размер блока файла.
— настройки для конкретной папки HDFS
— настройка для конкретного файла
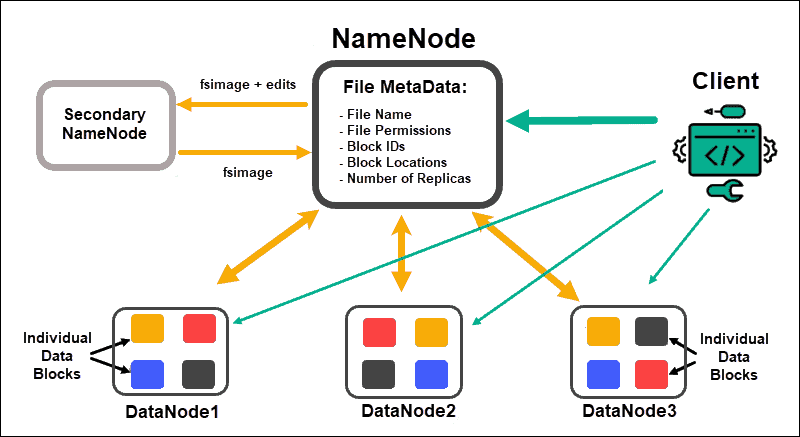
Блоки и файлы
Файл — это только запись в мета-данных на NameNode, содержимое же файла хранится в нескольких блоках одинакового размера на DataNode’ах. Основное назначение блоков в том чтобы сделать процесс чтения и записи предсказуемым. Сложно управлять одним большим файлом, переместить с одного сервера на другой, так как он может быть большим по объему. Когда нам нужно прочитать этот файл, то мы смотрим в справочник метаданных на NameNode и узнаем на каких DataNode’ах находятся блоки этого файла. Важно понимать, что DataNode’ы не знают что за блоки данных они хранят, к какому файлу они относятся и в случае выхода из строя NameNode’ы собрать блоки в единый файл не получится.
Размер блока для каждого файла можно настраивать в момент записи. Если у нас настроено, что 1 блок хранит 64 МБ данных, то файл размером 65 МБ будет распределен на 2 блока, где 1 блок имеет 64 МБ данных, а второй 1 МБ данных. Блоки как уже понятно нарезаются по размеру и все блоки кроме последнего имеют один и тот же размер. Размер блока после записи файла поменять нельзя, так как блоки уже распределены на разные сервера.
В HDFS существует проблема записи мелких файлов. NameNode хранит файлы в оперативной памяти, где как раз и лежит информация о связи файла с блоками и чем больше файлов, тем быстрее закончится место, поэтому важно следить за записью файлов и не плодить их с помощью мелких для экономии места в оперативной памяти NameNode. Примерный размер для хранения каждого такого файла равен 150 байт. Поэтому небольшие файлы в HDFS хранить неэффективно: много мелких файлов будут занимать много места на NameNode, больше, чем требуется для хранения их содержимого. Для сети в случае падения DataNode’ы проще дореплецировать 1 раз размер блока в 1 ГБ, чем 1000 мелких файлов в 1 МБ.
У каждого блока данных есть отдельный файл, который хранит 3 контрольные суммы (3 суммы нужны чтобы избежать коллизий). Этот файл с хэш суммами нужен чтобы проверить, что файл блока не битый. В HDFS есть процесс, который ходит по DataNode’ам и пересчитывает контрольные суммы файлов, это необходимо чтобы проверить, что блок не сломался или блок не изменен руками администратора.

Репликация — процесс создания копии данных с целью обеспечения сохранности данных, в случае потери одной реплики у нас всегда оставалась запасная, резервная. Создавая файл в HDFS можно указать размер файла (64 МБ по умолчанию) и кол-во реплик, по умолчанию 3. Для достижения максимальной надежности 2 и 3 реплика помещаются на разные стойки узлов данных. HDFS следит за тем, что если какие-то файлы у него недореплицированы, то он сам автоматически начинает их реплицировать до нужного количества.
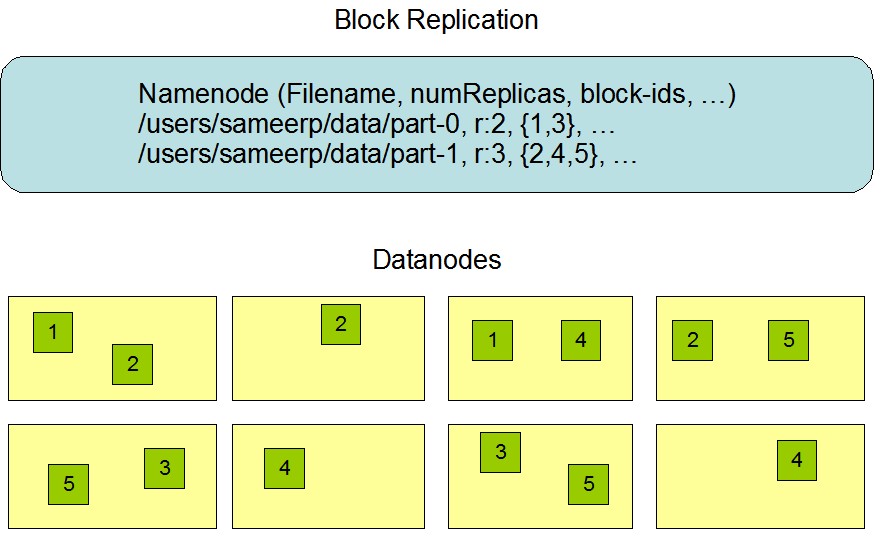
Чтение данных в HDFS
Клиент HDFS запрашивает информацию у NameNode через специальный интерфейс Distributed File System о файле, проверяет существует ли он, какие права доступа. В случае прохождения всех этапов проверки NameNode выдает клиенту информацию о файле, где находятся его блоки на DataNode. Получив эту информацию клиент с помощью интерфейса FSDataInputStream идет на каждую DataNode’у и выкачивает нужную информацию.
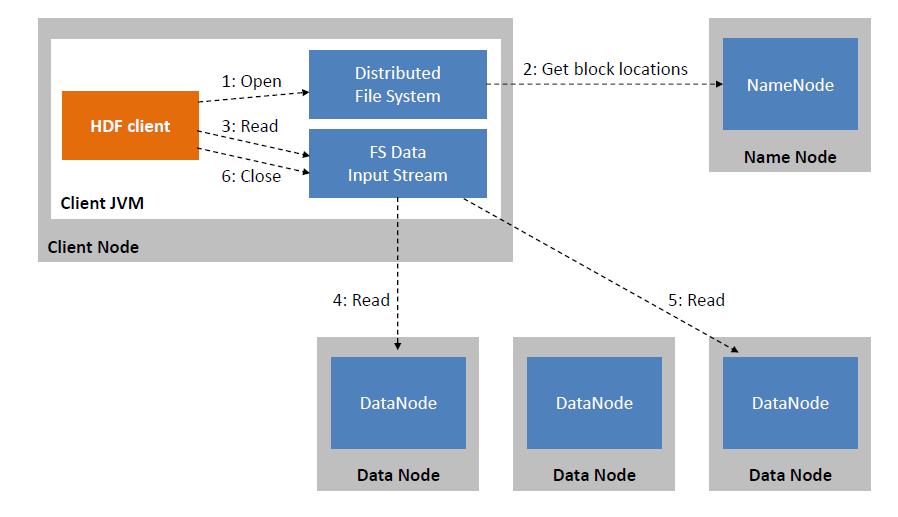
Запись данных в HDFS
Клиент HDFS иницирует запрос на запись файла к NameNode. NameNode со своей стороны проверяет существует ли такой файл и есть ли у клиента права на запись в этот файл. Если проверки прошли успешно, то NameNode в своих мета-данных создает запись для файла. Далее клиент делит файл на несколько пакетов согласно установленному размеру блока и управляет ими в форме очереди данных. HDFS последовательно отправляет пакеты на запись в DataNode’у, создавая новые блоки. Запись происходит в 1 DataNode, дальше идет репликация записанного блока на две другие DataNode’ы, как только репликация завершается клиенту возвращается подтверждение (ack packet) того что запись файла завершена успешно. Важно отметить, что клиенты пишут напрямую в DataNode’ы, минуя Namenode’у. Благодаря этому обеспечивается высокая надежность и пропускная способность.
Есть возможность либо удалить, либо записать файл заново, либо записать что-то в конец файла причем при записи в конец файла создается отдельный новый блок, в существующие блоки, даже если их размер не достигается предельного размера согласно настройкам HDFS, дозаписать что-то не получится. Аналогично и про запись в середину файла, такой возможности не предоставляется.
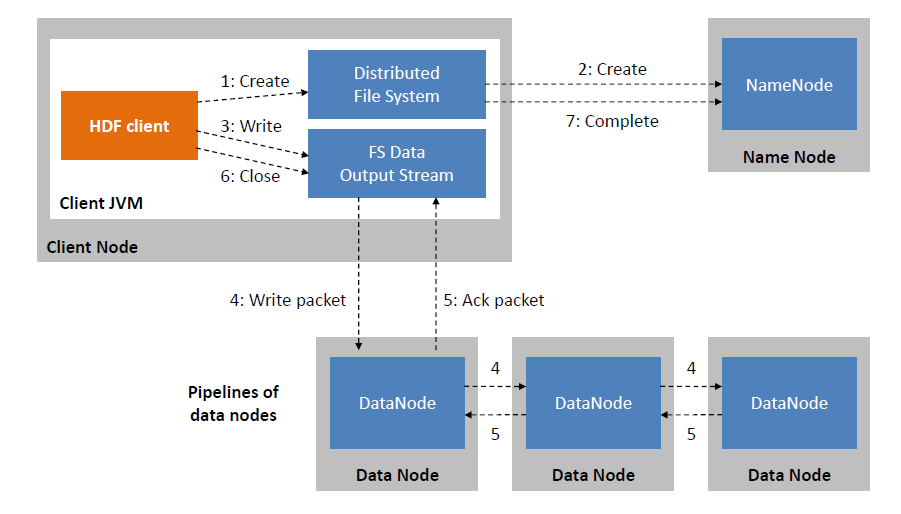
Высокая доступность
NameNode (standby) — это сервер, который необходим в случае если активная NameNode в кластере выведена из строя. В Journal Node пишутся все изменения, а NameNode (standby) читает эти изменения и становится управляющим NameNode кластера в случае потери активной NameNode.
YARN
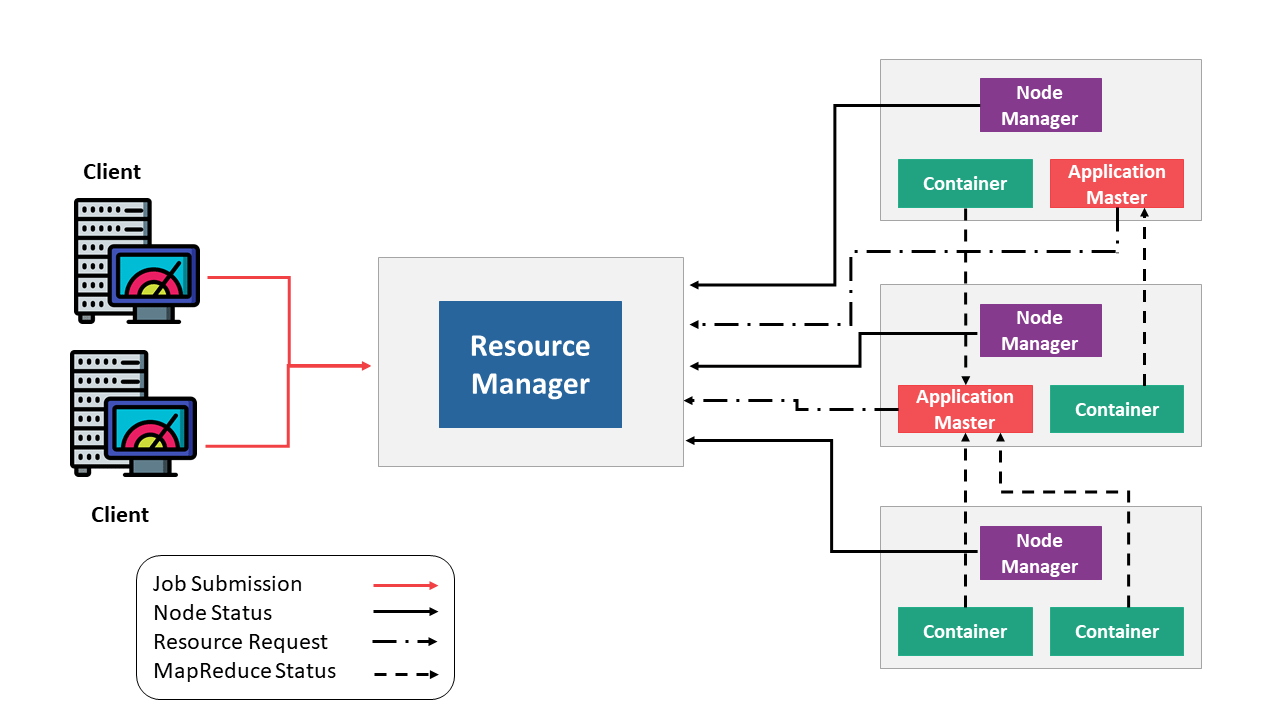
YARN (Yet Another Resource Negotiator) — модуль, отвечающий за управление ресурсами кластера и планирование заданий. YARN работает с Java контейнерами, похожая сущность что у Kubernetes и Mesos, но YARN больше заточен для экосистемы Hadoop. Основная идея YARN состоит в том, чтобы предоставить абстракцию управления ресурсами и запуск/мониторинг задач двум отдельным компонентам: глобальному менеджеру ресурсов Resource Manager и локальному серверному менеджеру Node Manager.
Resource Manager — планировщик ресурсов, абстрагирующий вычислительные ресурсы кластера и управляющий их предоставлением. Для выполнения заданий он оперирует контейнерами.
Resource Manager выполняет следующие задачи:
— принимает задание от Client
— смотрит на доступные ресурсы и выбирает сервер, на котором есть доступные ресурсы
— запускает на сервере Application Master для того, чтобы следить как выполняется задание, успешно ли оно выполняется
— передает задание Application Master
— выделяет по запросу Application Master контейнеры с ресурсами
Application Master — главный контейнер в YARN, который отвечает за координацию всех остальных контейнеров. Если выходит из строя Application Master, то все остальные контейнеры тоже отключаются. На Application Master запускается JAR файл приложения, переданный от клиента, дальше Application Master запрашивает у Resource Manager запуск контейнеров, Resource Manager опрашивает на каких Node Manager есть свободные ресурсы, определившись у каких серверов есть необходимые ресурсы Application Master отправляет запросы этим Node Manager для запуска контейнеров. Само приложение внутри контейнера может иметь свой планировщик ресурсов, который может запрашивать дополнительные ресурсы у Resource Manager.
Node Manager — процесс, работающий на каждом вычислительном узле и отвечающий за запуск контейнеров приложений, мониторинг использования ресурсов контейнера (процессор, память, диск, сеть) и передачу этих данных Resource Manager.
Разделение ресурсов
YARN может приоритезировать какому приложению в первую очередь выделить ресурсы. Настроить приоритезацию можно следующим образом:
— Отдельная очередь для долгих тяжелых задач
— Отдельная очередь для мелких ad-hoc запросов
— Отдельная очередь для обучения ML моделей
— Отдельная очередь на каждый отдел и т. д.
MapReduce
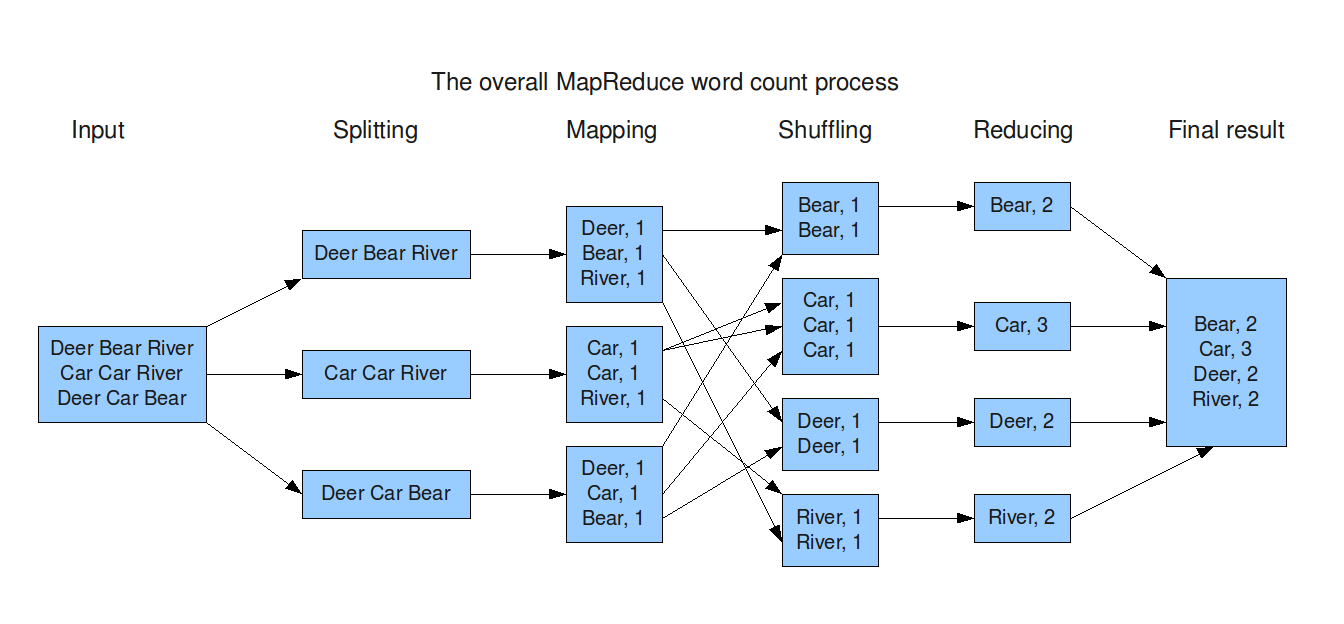
MapReduce — это фреймворк для обработки наборов данных с помощью параллельного распределенонго алгоритма.
Вычислительная модель MapReduce состоит из 3 этапов:
— map — каждый узел кластера, хранящий данные, применяет к каждой записи некоторую функцию и выдает результат в формате ключ-значение
— shuffle — перераспределение данных по сети по вычислительным узлам на основе ключей из этапа map
— reduce — применение агрегирующей функции к сгруппированным данным благодаря этапу shuffle и расчет финального результата
Достоинства такого фреймворка:
— Можно обрабатывать огромные объемы данных
— Отказоустойчивость при обработке
— Data Locality — данные хранятся на тех же узлах, где происходят вычисления
Недостатки:
— Частые операции чтения и записи на диск
— Ограниченная область применения
Hive
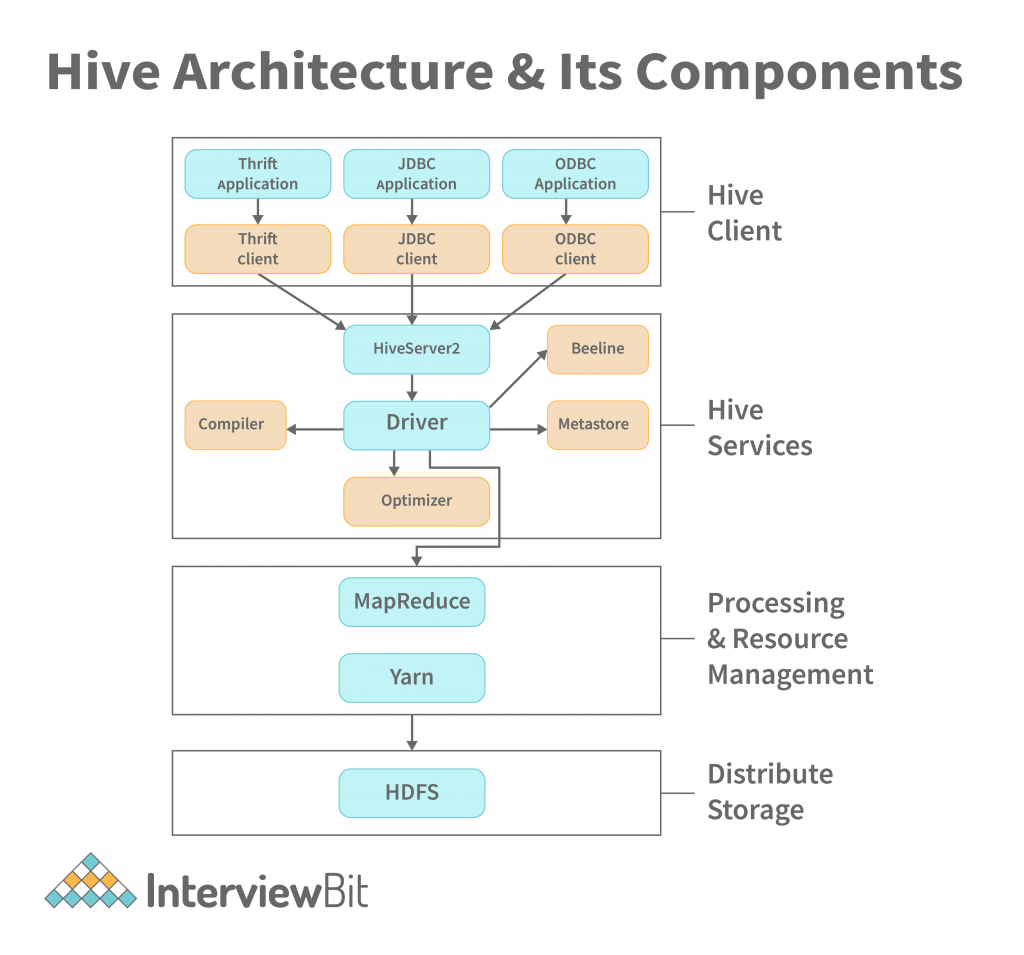
Hive — пользовательский интерфейс, где написанный клиентом SQL запрос преобразуется в MapReduce job и запускается на Hadoop. Благодаря Hive можно выполнять запросы к слабоструктурированным данным, для запросов используется специальный язык HiveQL. У Hive нет своего хранилища, но он имеет отдельную БД Hive Metastore для хранения метаданных о таблицах (структур таблиц).
Как выглядит архитектура Hive, клиенты отправляют SQL запрос на выполнение, запрос принимает HiveServer2, который отвечает за взаимодействие с клиентами. После запрос парсится с помощью компилятора для проверок наличия такой таблицы в Hadoop, следующим этапом запрос передается оптимизатору, после оптимизации запроса результат оптимизатора передается на исполнение в виде MapReduce job. Помимо MapReduce Hive может выполняться поверх Apache Spark. К сожалению, Hive — это все же не полноценная замена классической СУБД, также он не про скорость выполнения запроса, а про всеядность обработки больших объемов данных с понятным для пользователей интерфейсом, так как запуск job в YARN с процессом его приоритизаций, выделения ресурсов не быстрое действие.
Apache Hive Beeline — это клиент Hive для запуска HiveQL запросов с помощью командной строки.
Таблица в структуре Hive
Таблица в Hive представляет из себя аналог таблицы в классической реляционной БД. Основное отличие — что данные Hive’овских таблиц хранятся просто в виде обычных файлов на HDFS. Это могут быть обычные текстовые csv-файлы, бинарные sequence-файлы, более сложные колоночные parquet-файлы и другие форматы. Но в любом случае данные, над которыми настроена Hive-таблица, очень легко прочитать и не из Hive
Таблицы в hive бывают двух видов:
— классическая таблица, куда данные добавляются при помощи HiveQL
— внешняя таблица, данные в которую загружаются внешними системами, без участия Hive. Для работы с внешними таблицами при создании таблицы нужно указать ключевое слово EXTERNAL, а также указать путь до папки, по которому хранятся файлы
Партиции в Hive
Так как Hive представляет из себя движок для трансляции SQL-запросов в mapreduce-задачи, то обычно даже простейшие запросы к таблице приводят к полному сканированию данных в этой таблицы. Для того чтобы избежать полного сканирования данных по некоторым из колонок таблицы можно произвести партиционирование этой таблицы. Это означает, что данные относящиеся к разным значениям будут физически храниться в разных папках на HDFS. Партиции в Hive это не тоже самое что партиции в Oracle или другой реляционной СУБД, так как отдельные секционированные части хранятся в разных файлах на HDFS. Партиционирование в Hive является нативным функционалом и не требует создания подтаблиц как в случае с реляционными СУБД. Все партиции создаются автоматически и распределяются в каталогах HDFS.
MSCK REPAIR TABLE
У Hive нет контроля над хранилищем HDFS и если случилось так, что в папку таблицы были записаны данные отличным от Hive инструментом, например, Apache Spark, то Hive не увидит эти изменения. Чтобы избавиться от несогласованности данных в этой таблице необходимо выполнить команду MSCK REPAIR TABLE. Благодаря этой команде Hive проанализирует таблицу и новые партиции станут доступны в Hive.
Форматы хранения данных в Hadoop
Основными форматами хранения в Hadoop являются:
— Parquet
— ORC
— Avro
Parquet и ORC — это колоночный формат хранения данных, а Avro является построчным форматом. Одним из плюсов перечисленных форматов в том, что в них записана схема, то есть указаны какие поля есть в таблице, какого они типа. Помимо этого плюсом колоночного формата хранения является то, что каждый столбец таблицы — это отдельный файл в HDFS, что позволяет гораздо быстрее считывать данные по сравнению с построчным хранением данных. В случае если нам нужна высокая скорость записи широких по столбцам таблиц, то необходимо присмотреться на строковый формат хранения Avro.
При выборе между Parquet и ORC нужно понимать в чем их принципиальные отличия:
— Формат Parquet лучше хранит вложенные данные, например, колонки формата json
— У Parquet в метаданных колонок хранятся разные статистики по типу max, min, count, это может значительно сократить время подсчета агрегатов
— ORC поддерживает ACID-свойства
— ORC эффективнее сжимает данные чем Parquet