
Apache Airflow

Предпоссылки создания Apache Airflow
В 2014 году компания Airbnb стремительно развивалась, что привело к увеличению объема данных и усложнению рабочих процессов обработки данных. Управление этими сложными конвейерами данных с помощью традиционных инструментов, таких как Cron и пользовательские скрипты, стало нецелесообразным из-за недостаточной масштабируемости, гибкости и возможностей мониторинга. Airbnb требовалось решение, которое могло бы масштабироваться в соответствии с растущими потребностями в данных.Им требовалось отслеживать состояния рабочих процессов и возможность эффективно отлаживать сбои. Инициатива со стороны Maxime Beauchemin привела к созданию масштабируемого, гибкого и удобного инструмента управления рабочими процессами под названием Airflow. Сделав Airflow open-sourceным и наладив взаимодействие с сообществом, Airbnb не только решила свои внутренние проблемы, но и предоставила мощный инструмент широкому сообществу разработчиков. Сегодня Apache Airflow широко используется в различных отраслях индустрии для организации сложных рабочих процессов и конвейеров данных.
Apache Airflow — фреймворк для построения конвейров обработки данных. Airflow сам по себе не является инструментом обработки данных. Он управляет различными компонентами, которые отвечают за обработку ваших данных в конвейерах. Ключевая особенность Airflow заключается в том, что он позволяет легко создавать конвейеры обработки данных, запускаемых по расписанию с помощью языка Python.
Какие задачи решает Airflow?
- Оркестрация рабочих процессов: Airflow позволяет управлять зависимостями между задачами, обеспечивая их выполнение в нужном порядке
- Планирование задач: С помощью Airflow можно запланировать выполнение задач по заданному расписанию
- Мониторинг и управление задачами: Airflow предоставляет интерфейс для отслеживания выполнения задач, просмотра логов и управления задачами в реальном времени
- Интеграция с различными системами: Airflow может взаимодействовать с различными источниками данных и системами, такими как базы данных, облачные сервисы, API и другие.
- Автоматизация процессов: Airflow помогает автоматизировать повторяющиеся процессы, что снижает ручной труд и минимизирует ошибки.
- Логирование и отслеживание изменений: Airflow сохраняет логи выполнения задач, что помогает в отладке и анализе процессов.
Кому подойдет Airflow
— Для планирования задач, где возможностей Cron стало недостаточно
— У команды уже есть достаточная экспертиза в программировании на Python
— На проекте используется пакетная обработка данных (Batch), а не потоковая (Stream). AirFlow предназначен для Batch-заданий, для потоковой обработки данных лучше использовать Apache NiFi
— Планируется или уже осуществлен переход в облако и необходим надежный оркестратор, поддерживающий все принципы Cloud-Native
Конвейеры обработки данных в виде графов
Конвейер обработки данных легко представить в виде графа. В математике граф представляет собой конечный набор узлов с вершинами, соединяющими узлы. В контексте разработки каждый узел в графе представляет собой задачу, а зависимостями между задачами — направленные ребра между узлами. Ребро, направленное от задачи A к задаче B, указывает, что задача A должна быть завершена до того, как может начаться задача B. Такие графы обычно называются ориентированными, или направленными, потому что ребра имеют направление.
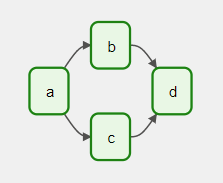
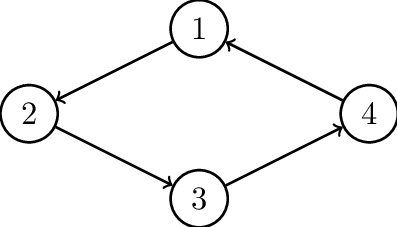
Данный тип графа обычно называется ориентированным ациклическим графом, поскольку он содержит ориентированные ребра и у него нет никаких петель или циклов (ациклический).
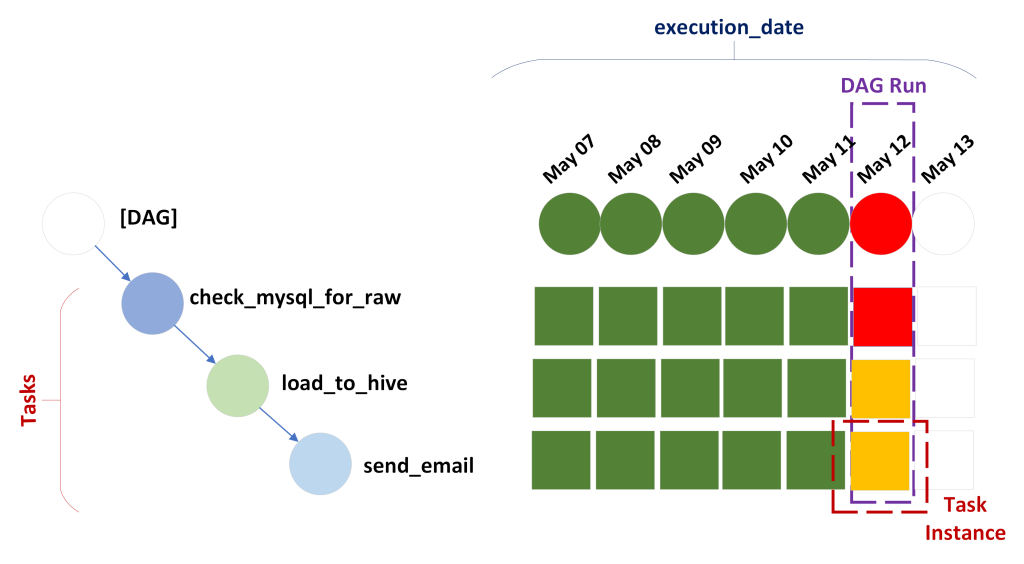
Анатомия DAG в Airflow
DAG (Directed Acyclic Graph) — направленный ациклический граф необходимый для смыслового объединения изолированных задач, которые необходимо выполнить в строго определенной последовательности согласно указанному расписанию. Задачами же в терминологии Airflow называют Task. Под задачами понимается, например, загрузка из различных источников, их агрегирование, очистка от дубликатов, сохранение полученных результатов и прочие ETL-процессы. На уровне кода задачи представляют собой Python-функции или Bash-скрипты в терминологии Airflow их называют Operator.
Task — это внутренние компоненты для управления состоянием operator и отображения изменений состояния (например, запущено/завершено) для пользователя. Task управляет выполнением оператора.
Operator — отвечает за выполнение одной единицы работы. Операторы — это некие готовые шаблоны, которые можно переиспользовать, реализующие логику выполнения (запуск скрипта, команды, обращение к СУБД) с набором параметров на входе. В AirFlow богатый выбор встроенных операторов. Кроме этого, доступно множество специальных операторов — путем установки пакетов поставщиков, поддерживаемых сообществом. Также возможно добавление пользовательских операторов — за счет расширения базового класса BaseOperator.
Sensor — это особая группа операторов, которые позволяют в случае наступления определенного события запустить выполнение следующих по зависимости задач. В качестве триггера могут выступать получение некоторого файла, готовность данных на источнике и так далее.
Так как Airflow оперирует языком Python, то у класса DAG могут быть свои экземпляры. В Airflow экземплярами DAGа называют DAG Run, связанные с этим DAGом экземляры задач — task Instance, а время запуска этих DAGов — execution_date (в более поздних версиях Airflow logical_date).
Архитектура Airflow и принципы его работы
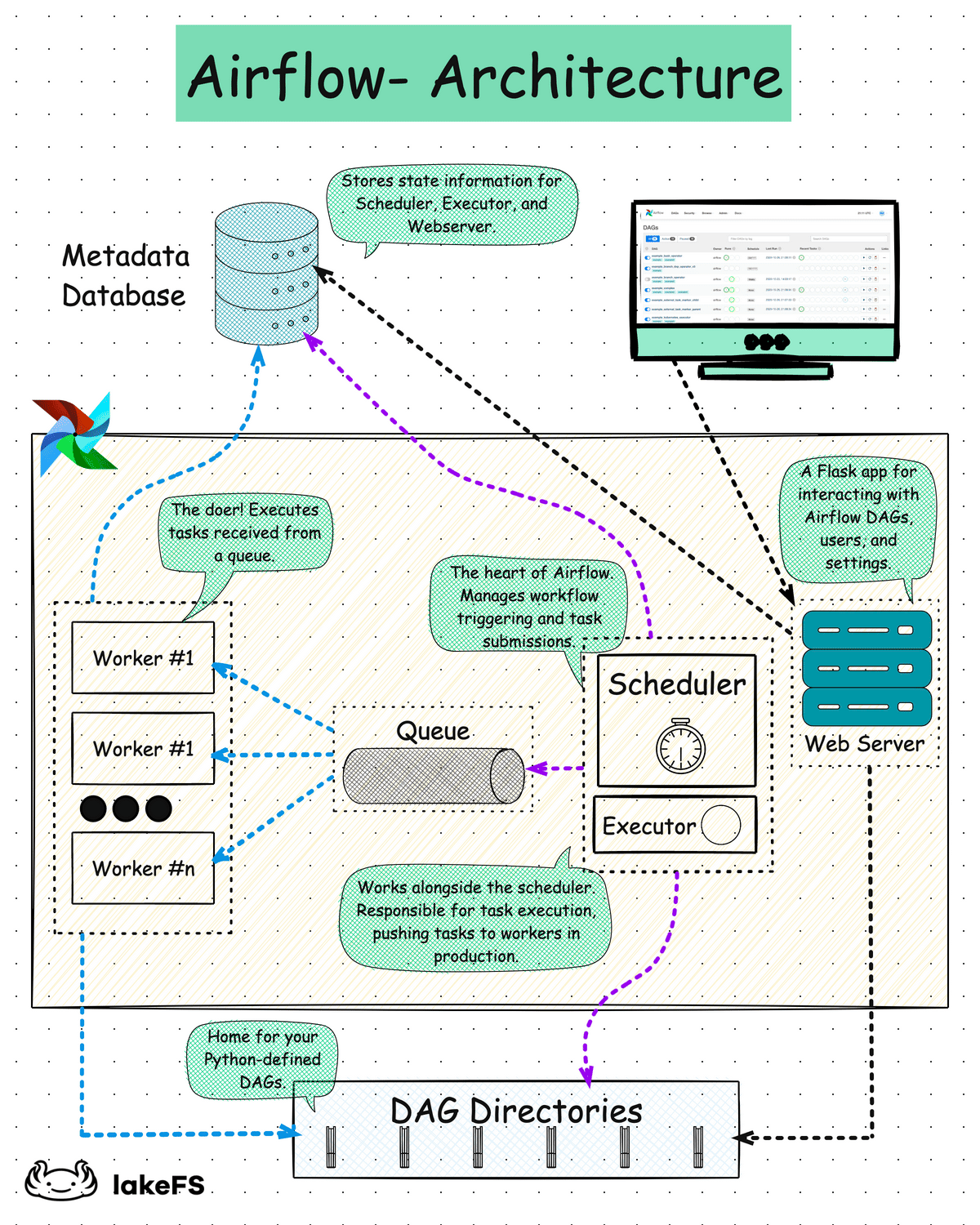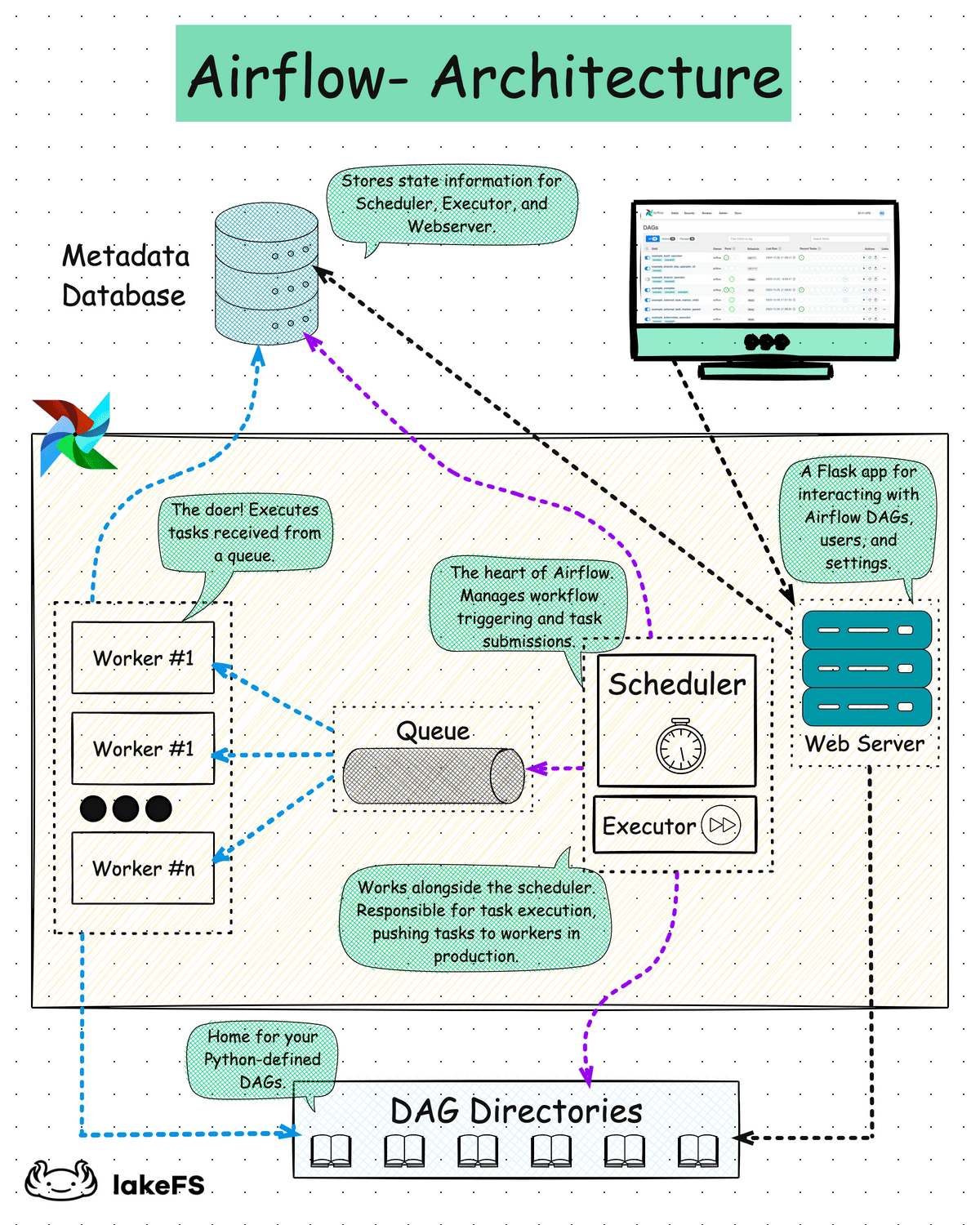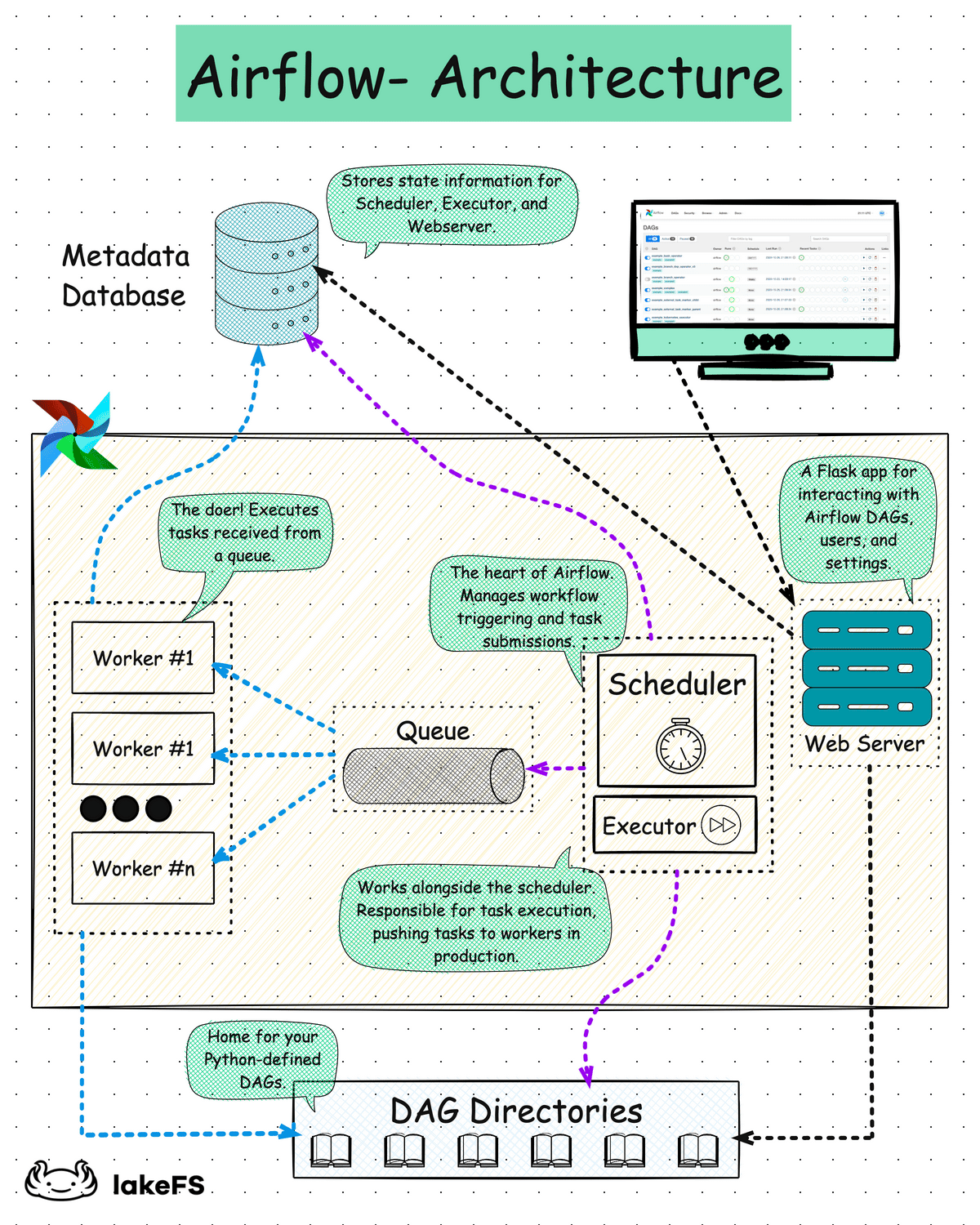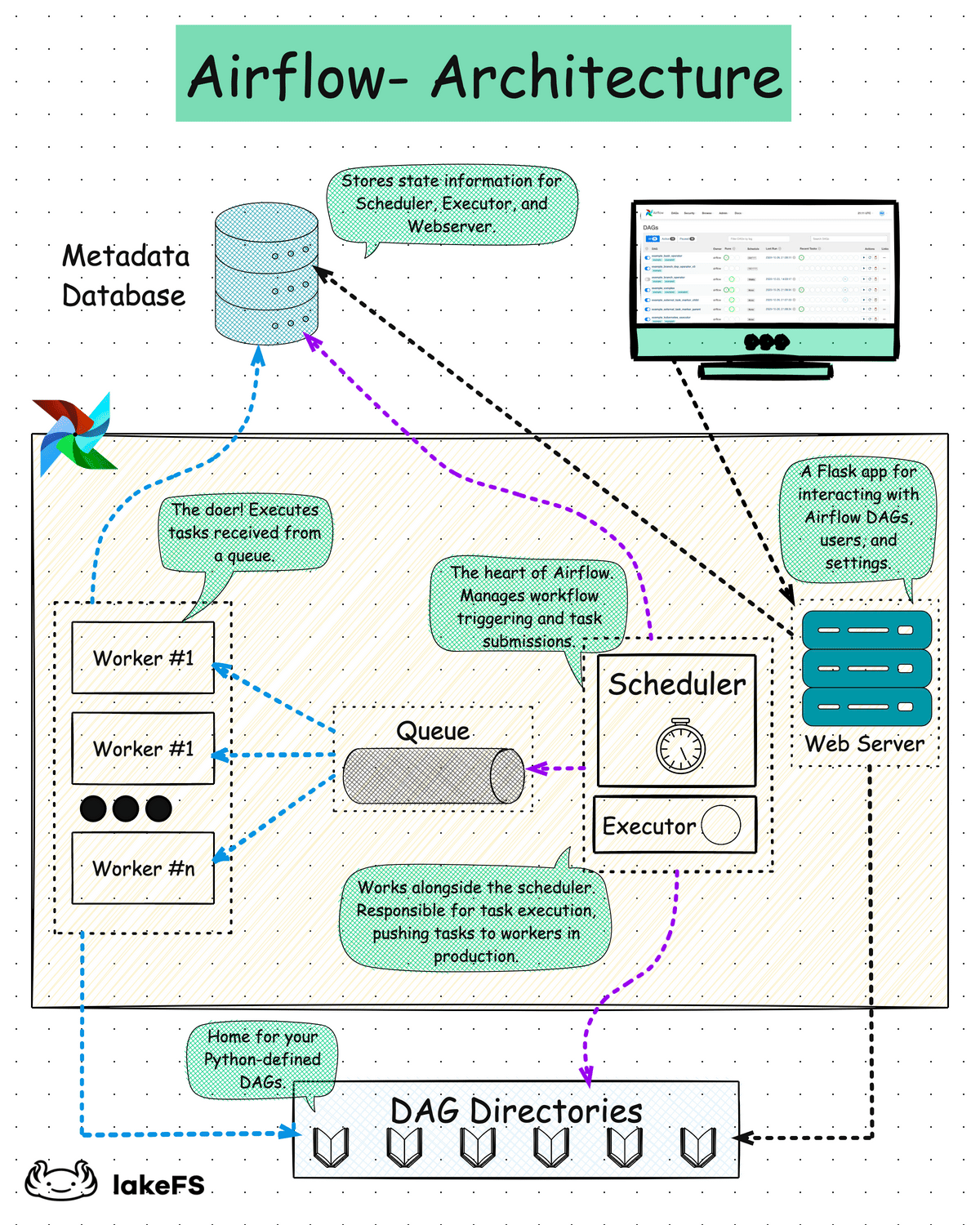
Web Server — компонент, который позволяет визуализировать зависимости в Airflow, анализируемые планировщиком, и предоставляет пользователям основной интерфейс для отслеживания выполнения графов и их результатов. Помимо этого представления, Airflow также предоставляет подробное древовидное представление, в котором показаны все текущие и предыдущие запуски соответствующего DAG. Также здесь приводится беглый обзор того, как работал DAG, и оно позволяет покопаться в задачах, завершившихся сбоем, чтобы увидеть, что пошло не так.
Metadata DB (база метаданных) — собственный репозиторий метаданных на базе библиотеки SqlAlchemy для хранения глобальных переменных, настроек соединений с источниками данных, статусов выполнения Task Instance, DAG Run и так далее. Хранит состояния scheduler, executor и веб-сервера. Требует установки совместимой с SqlAlchemy базы данных, например, MySQL или PostgreSQL.
Scheduler (планировщик) — служба, отвечающая за планирование в Airflow и отправку задания на исполнение. Отслеживая все созданные Task и DAG, планировщик инициализирует Task Instance — по мере выполнения необходимых для их запуска условий. По умолчанию раз в минуту планировщик анализирует результаты парсинга директории dags и проверяет, нет ли задач, готовых к запуску.Если все в порядке,то начинает планировать задачи DAG для выполнения, передавая их воркерам Airflow. Для выполнения активных задач планировщик использует указанный в настройках Executor. Для определенных версий БД (PostgreSQL 9.6+ и MySQL 8+) поддерживается одновременная работа нескольких планировщиков — для максимальной отказоустойчивости.
Executor (исполнитель)— часть scheduler, механизм, с помощью которого запускаются экземпляры задач. Работает в связке с планировщиком в рамках одного процесса.
Worker (рабочий) — отдельный процесс, в котором выполняются запланированные задачи. Размещение Worker — локально или на отдельной машине — определяется выбранным типом Executor. Допускается неограниченное число DAG за счет модульной архитектуры и очереди сообщений. Worker могут масштабироваться при использовании Celery или Kubernetes.
DAG Directory — каталог исполняемых DAGов для остальных компонентов Airflow
Концепция планирования в Airflow
Выполнение работы с фиксированными интервалами
Для многих рабочих процессов, включающих временные процессы, важно знать, в течение какого временного интервала выполняется данная задача. По этой причине Airflow предоставляет задачам дополнительные параметры, которые можно использовать, чтобы определить, в каком интервале выполняется задача. Самый важный из этих параметров — execution_date, который обозначает дату и время, в течение которых выполняется DAG. execution_date (начиная с версии Airflow версии 2.2 logical_date) — это не дата, а временная метка, отражающая время начала интервала, для которого выполняется DAG. Время окончания интервала указывается другим параметром, next_execution_date (data_interval_end в поздних версиях Airflow 2). Вместе эти даты определяют всю продолжительность интервала задачи.
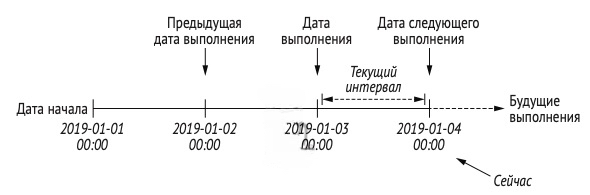
Предположим, что у нас есть DAG, который следует ежедневному интервалу, а затем учитывает соответствующий интервал, в котором должны обрабатываться данные за 2019-01-03. В Airflow этот интервал будет запускаться вскоре после 2019-01-04:00:00, потому что в данный момент мы знаем, что больше не будем получать новые данные за 2019-01-03. Значение переменной execution_date при выполнении задач будет 2019-01-03. Это связано с тем, что Airflow определяет дату выполнения DAG как начало соответствующего интервала. Дата выполнения отмечает интервал, а не момент фактического выполнения DAG.
Запуск через равные промежутки времени
Airflow можно запускать через равные промежутки времени, задав для него запланированный интервал с помощью аргумента schedule_interval при инициализации DAG.
dag = DAG(
dag_id="dag_1", schedule_interval="@daily" <-- Планируем запуск каждый день в полночь
, start_date=dt.datetime(2019, 1, 1) <-- Дата и время начала планирования запусков DAG
... )Airflow также нужно знать, когда мы хотим начать выполнение DAG, указав дату запуска. Исходя из этой даты, Airflow запланирует первое выполнение нашего DAG. Airflow запускает задачи в конце интервала. Если разработанный DAG вывели на продуктив 1 января 2019 года в 14:00 с start_date — 01-01-2019 и интервалом @daily, то это означает, что первый DAG Run случится в полночь 02-01-2019:00:00.
Интервалы на основе Cron
Для поддержки более сложных вариантов Airflow позволяет определять интервалы, используя тот же синтаксис, что и у cron — планировщика заданий на основе времени, используемого Unix-подобными операционными системами, такими как macOS и Linux. Достаточно указать crontab выражение в аргументе schedule_interval при инициализации DAGа.
from airflow.models.dag import DAG
import datetime
dag = DAG("regular_interval_cron_example", schedule="0 0 * * *", ...) <-- задача будет регулярно запускаться в полночьЧастотные интервалы
Если мы хотим запускать наш DAG раз в три дня, то в качестве интервала можно передать экземпляр timedelta (из модуля datetime в стандартной библиотеке Python) в schedule_interval.
— timedelta(minutes=10) каждые 10 минут
— timedelta(hours=2) каждые 2 часа
dag = DAG(
dag_id="dag_3", schedule_interval=dt.timedelta(days=3),
......)Правила триггеров
Правила триггеров — это, по сути, условия, которые Airflow применяет к задачам, чтобы определить, готовы ли они к выполнению, ориентируясь на их зависимости. Правило триггеров по умолчанию — это all_success, которое гласит, что все зависимости задачи должны быть успешно завершены, прежде чем саму задачу можно будет выполнить.
А что произойдет, если одна из наших задач обнаружит ошибку во время исполнения? Это означает, что нижестоящую задачу уже нельзя выполнить, поскольку для ее успешного выполнения необходима успешное выполнение предшествующей задачи и она примет статус upstream_failed. Более подробно со статусами задач можно ознакомиться в официальной документации Airflow.
Airflow поддерживает и другие правила триггеров, которые допускают различные типы поведения при ответе на успешные, неудачные или пропущенные задачи. Правило none_failed означает, что оно допускает как успешные, так и пропущенные задачи, по-прежнему ожидая завершения всех вышестоящих задач, перед тем как продолжить. Например, правило all_done можно использовать для определения задач, которые завершили свое выполнение независимо от их конечного состояния. Более подробно об остальных правилах можно познакомиться в официальной документации Airflow

Запуск задачи после определенного действия
Действия, связанные с запуском, часто являются результатом внешних событий. Представьте себе файл, который публикуется на общий диск, готовность данных за конкретную дату во внешней БД и т. д. Для решения подобных задач используют сенсоры, представляющие собой особый тип (подкласс) операторов. Сенсоры непрерывно опрашивают определенные условия, чтобы определить их истинность, и если условие истинно, то сенсор завершает свою работу со статусом успешно. В противном случае сенсор будет ждать и повторять попытку до тех пор, пока условие не будет истинно, или время ожидания истечет.
from airflow.sensors.filesystem import FileSensor
wait_for_supermarket_1 = FileSensor(
task_id="wait_for_data",
filepath="data.csv",
)Здесь FileSensor выполняет проверку на предмет наличия файла data.csv и возвращает true, если файл существует. В противном случае возвращается false, и сенсор будет ждать в течение заданного периода (по умолчанию 60 секунд) и повторит попытку.
Вывод сенсоров можно посмотреть в логах задач:
{file_sensor.py:60} INFO – Poking for file data.csv
{file_sensor.py:60} INFO – Poking for file data.csv
{file_sensor.py:60} INFO – Poking for file data.csv
{file_sensor.py:60} INFO – Poking for file data.csv
{file_sensor.py:60} INFO – Poking for file data.csvЗдесь видно, что примерно раз в минуту сенсор осуществляет покинг на предмет наличия определенного файла. Покинг — так в Airflow называется запуск сенсора и проверка условия.
Зачастую сенсоры добавляются в самое начало DAGа, так как мы хотим запустить последующие манипуляции с данными только в случае их готовности на источнике. Таким образом, сенсоры в начале DAG будут непрерывно выполнять опрос на предмет наличия данных и переходить к следующей задаче после выполнения условия.
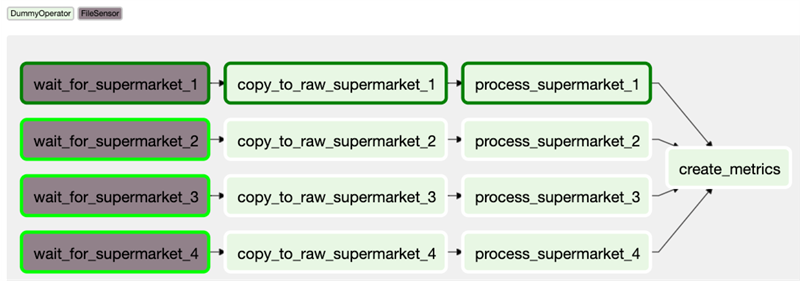
А что произойдет, если однажды один из источников не предоставит свои данные за ожидаемое время? По умолчанию сенсоры будут падать, как и зависимые от них задачи со статусом upstream_failed. Сенсоры принимают аргумент timeout, который содержит максимальное количество секунд, в течение которого сенсор может работать. Если в начале очередного покинга количество секунд превысит число, заданное для timeout, то это приведет к падению сенсора.
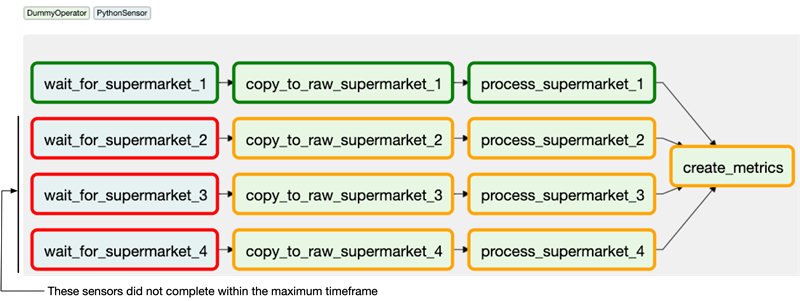
Количество задач (на разных уровнях), которые Airflow может обработать ограничено. Важно понимать, что в Airflow есть ограничения на максимальное параллельное количество выполняемых задач на разных уровнях; количество задач на каждый DAG, количество задач на глобальном уровне Airflow, количество запусков DAG на каждый DAG и т. д. У класса DAG есть аргумент concurrency, определяющий, сколько параллельных задач разрешено в рамках этого DAG. Таким образом каждый сенсор — это одна задача и в случае если у вас их много и значение concurrency меньше кол-ва сенсоров, то некоторые сенсоры будут простаивать и не запускать проверку своего условия, эти сенсоры будут ожидать пока освободится слот в DAGе, то есть пока не завершит свое выполнение один из ранее запустившихся сенсоров.
Класс сенсора принимает аргумент mode, для которого можно задать значение poke или reschedule (начиная с Airflow версии 1.10.2). По умолчанию задано значение poke, что приводит к блокировке. Это означает, что задача сенсора занимает слот, пока выполняется. Время от времени она выполняет покинг, осуществляя проверку условия, а затем ничего не делает, но по-прежнему занимает слот. Режим сенсора reschedule освобождает слот после покинга, слот остается занят только когда выполняется проверка.
Запуск задач с помощью REST API и интерфейса командной строки
Запуск DAGов можно осуществлять через REST API и командную строку. Это может быть полезно, если вы хотите запускать рабочие процессы за пределами Airflow. Данные, поступающие в случайное время в бакет AWS S3, можно обрабатывать, задав лямбда-функцию для вызова REST API, запуская DAG, вместо того чтобы постоянно запускать опрос с сенсорами.
airflow dags trigger dag1Этот код запускает dag1 с датой выполнения, установленной на текущую дату и время. Идентификатор запуска имеет префикс manual__, указывая на то, что он был запущен вручную или за пределами Airflow.
Для обеспечения аналогичного результата можно использовать REST API (например, если у вас нет доступа к командной строки, но к вашему экземпляру Airflow можно подключиться по протоколу HTTP).
Преимущества и недостатки Airflow
Преимущества:
— Airflow — это фреймворк с открытым исходным кодом
— Конвейеры на основе кода обладают большими возможностями расширения. Преимущество того факта, что Airflow написан на языке Python, состоит в том, что задачи могут выполнять любую операцию, которую можно реализовать на Python. Со временем это привело к разработке множества расширений Airflow, позволяющих выполнять задачи в широком спектре систем, включая внешние базы данных, технологии больших данных и различные облачные сервисы, давая возможность создавать сложные конвейеры обработки данных, объединяющие процессы обработки данных в различных системах
— Конвейеры на основе кода более управляемы: поскольку все находится в коде, он может легко интегрироваться в ваш CI / CD управления версиями и общие рабочие процессы разработчика.
— Множество интеграций с разными системами
— Гибкий планировщик
— Возможность масштабирования
— Такие функции, как обратное заполнение (backfill), дают возможность с легкостью (повторно) обрабатывать архивные данные, позволяя повторно вычислять любые производные наборы данных после внесения изменений в код;
— Многофункциональный веб-интерфейс Airflow обеспечивает удобный просмотр результатов работы конвейера и отладки любых сбоев, которые могут произойти
— Поддерживаются все принципы Cloud-Native
Недостатки:
— Обработка потоковых конвейеров, поскольку Airflow в первую очередь предназначен для выполнения повторяющихся задач по пакетной обработке данных, а не потоковых рабочих нагрузок
— Реализация высокодинамичных конвейеров, в которых задачи добавляются или удаляются между каждым запуском конвейера. Хотя Airflow может реализовать такое динамическое поведение, веб-интерфейс будет показывать только те задачи, которые все еще определены в самой последней версии DAG. Таким образом, Airflow отдает предпочтение конвейерам, структура которых не меняется каждый раз при запуске
— Поддержка Airflow может быстро стать сложной в крупных проектах
— Высокий порог входа в фреймворк