Что такое жизненный цикл работы с данными?
Жизненный цикл работы с данными содержит этапы, где мы трансформируем сырые данные из источников в финальный, готовый к использованию продукт, которым могут воспользоваться такие специалисты как: дата аналитики, data scientistы, ML инженеры. В данной главе сфокусируемся на каждом этапе, раскроем их главные концепции.
Жизненный цикл работы с данными состоит из:
— генерации данных
— загрузки и сбора данных
— трансформации данных
— предоставлении данных конечным потребителям
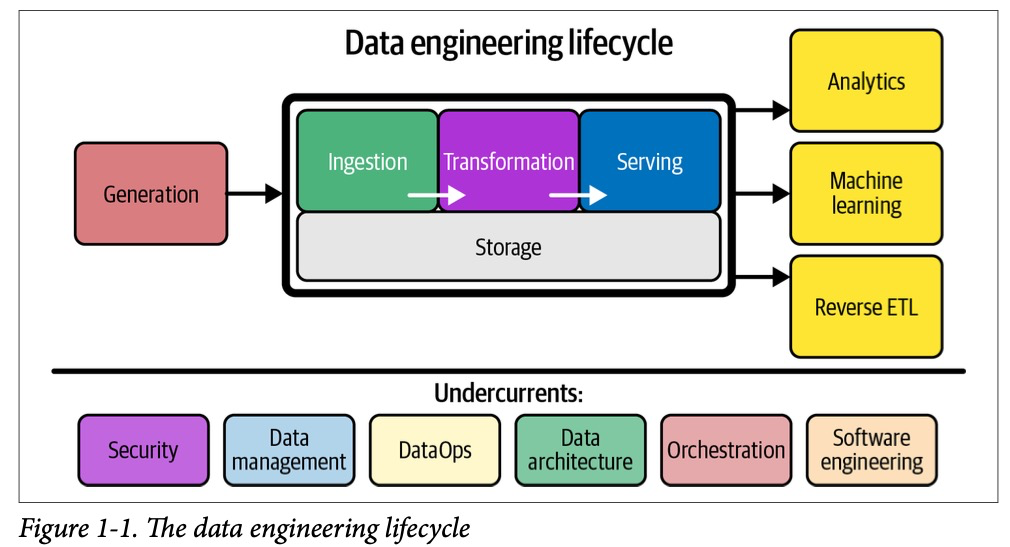
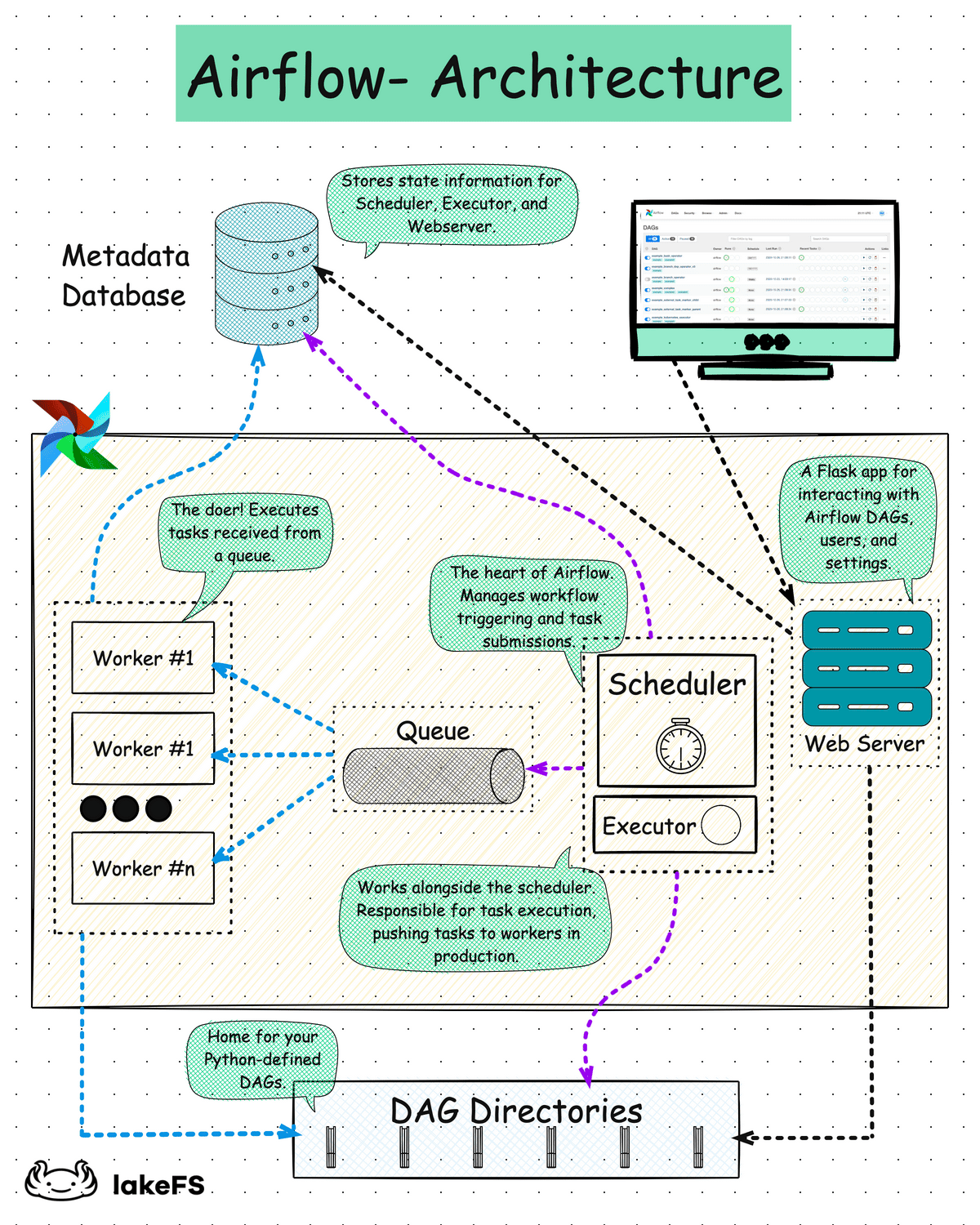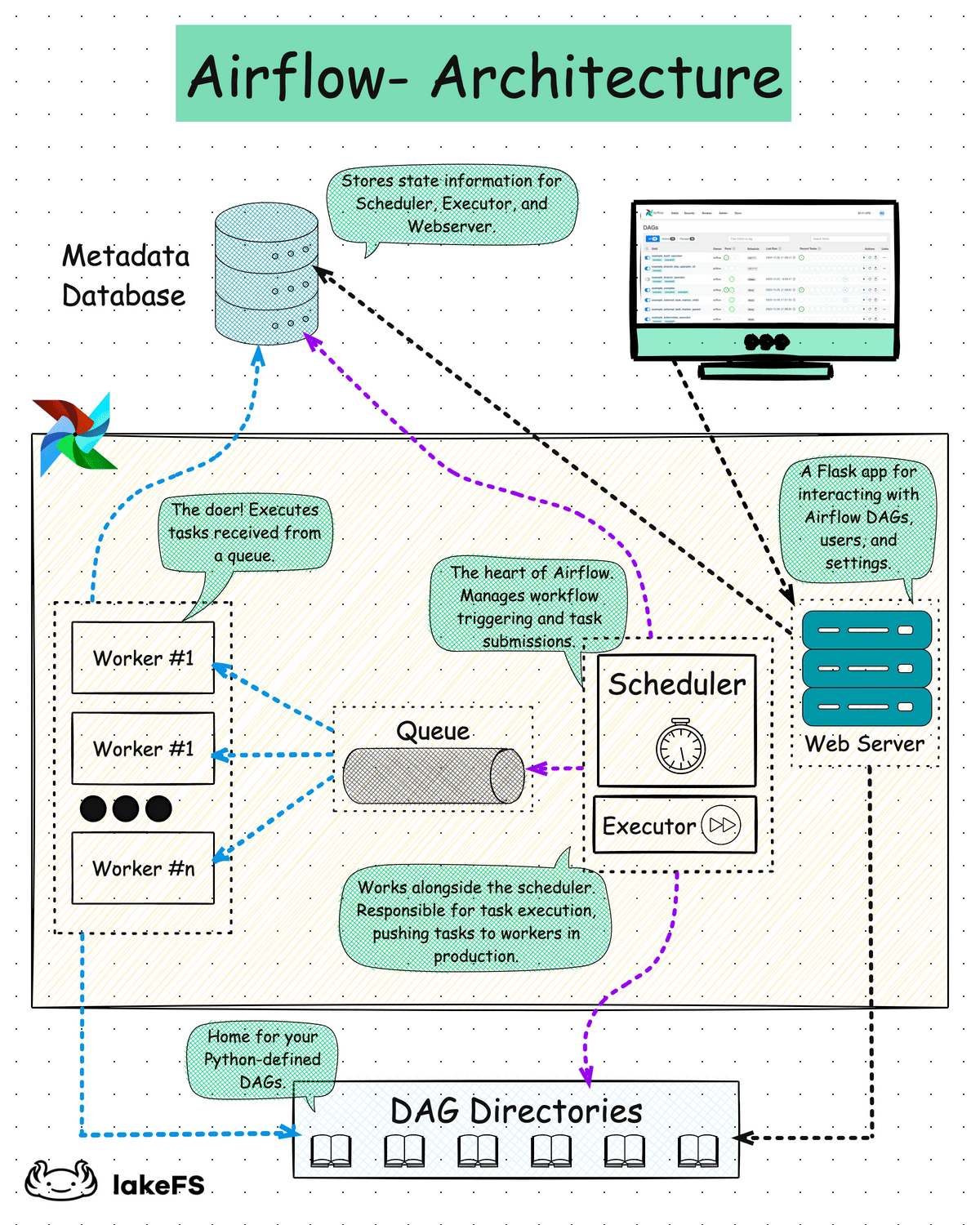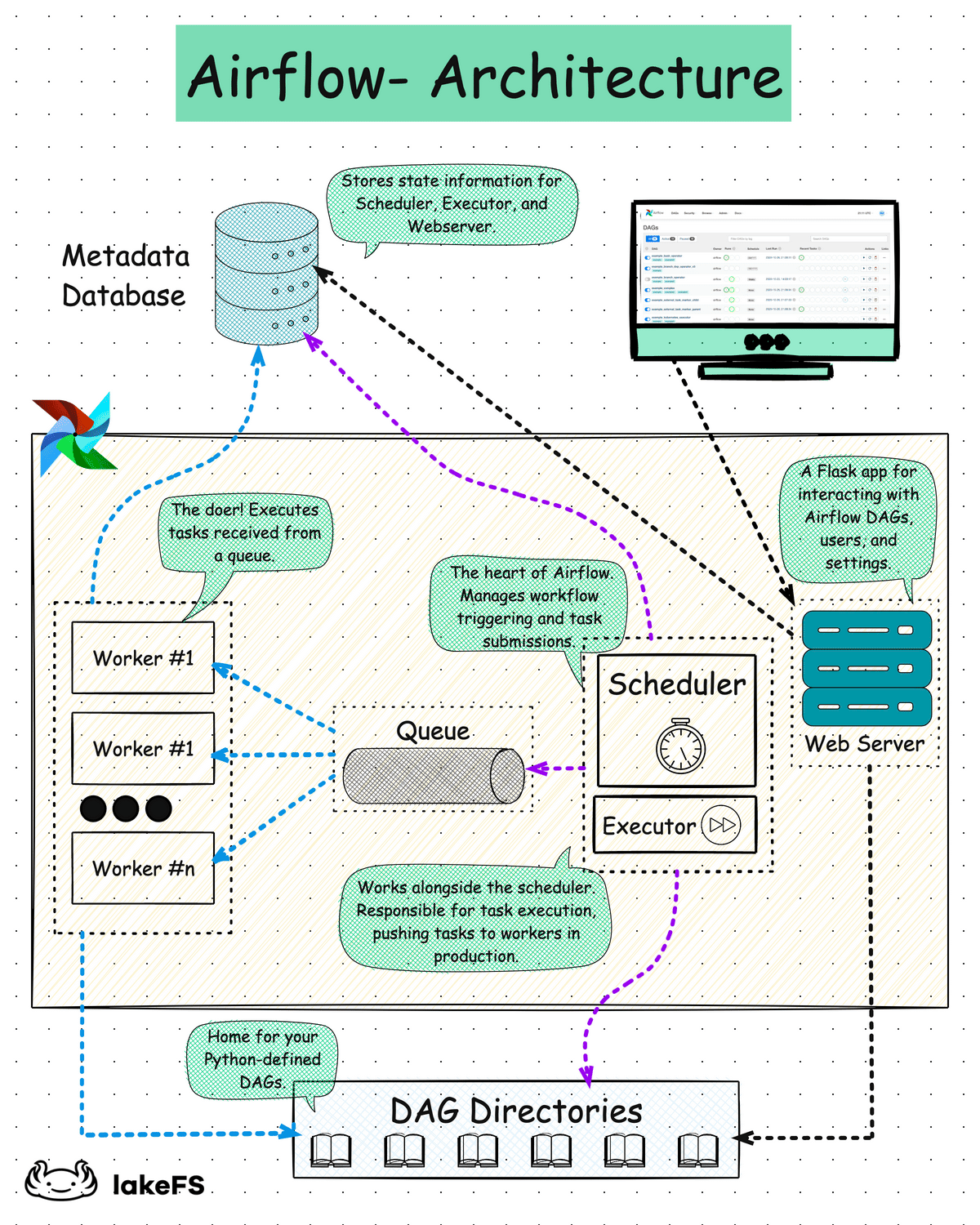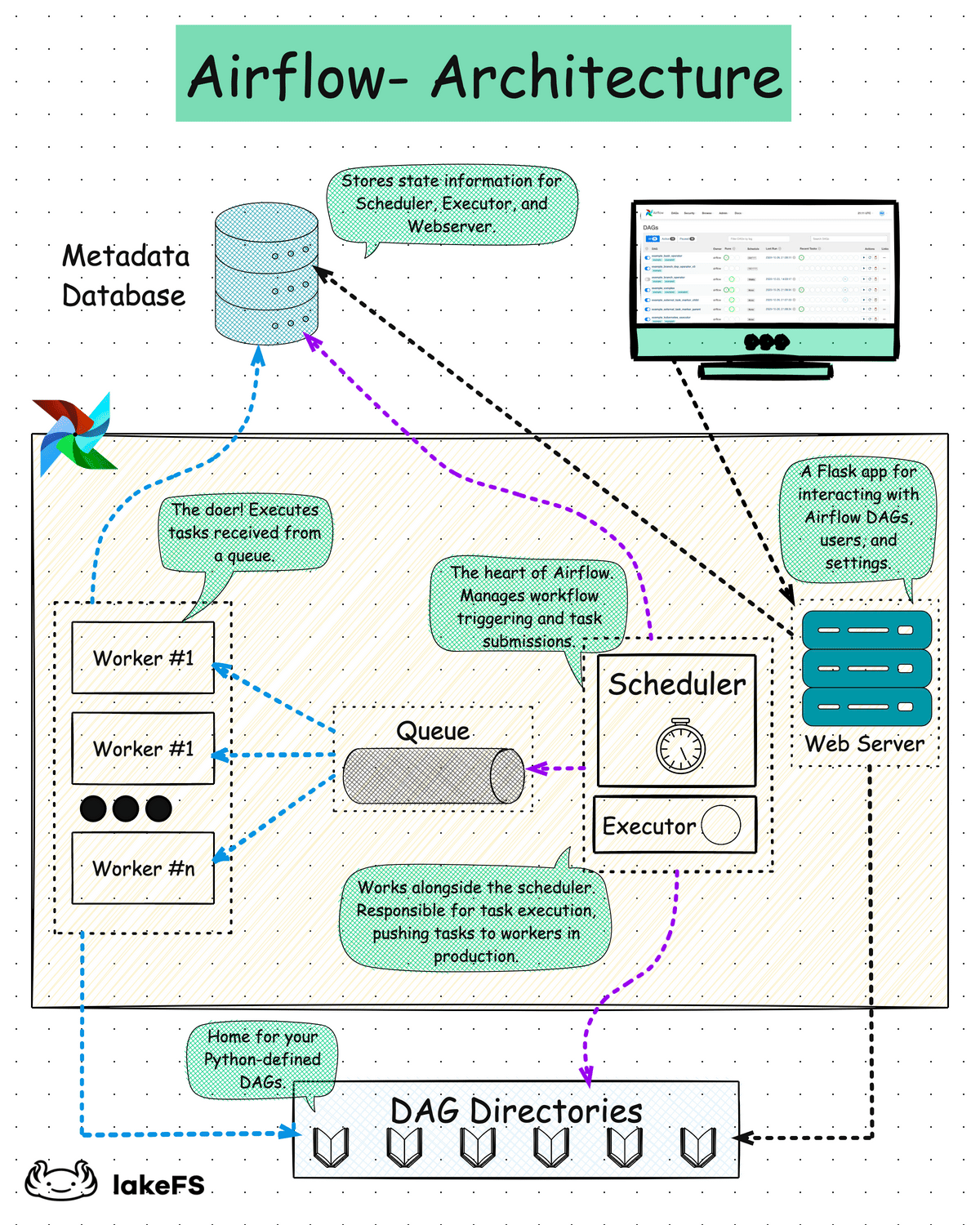
Процесс хранения данных протекает через весь жизненный цикл работы с данными от самого начала до конца. На диаграмме «1-1» демонстрируется, что этап хранения является ключевым для всех вышестоящих этапов.
Жизненный цикл работы с данными гибок, и его этапы (хранение, сбор, преобразование) не всегда следуют строгому порядку, а могут пересекаться или происходить в разных последовательностях в зависимости от ситуации.
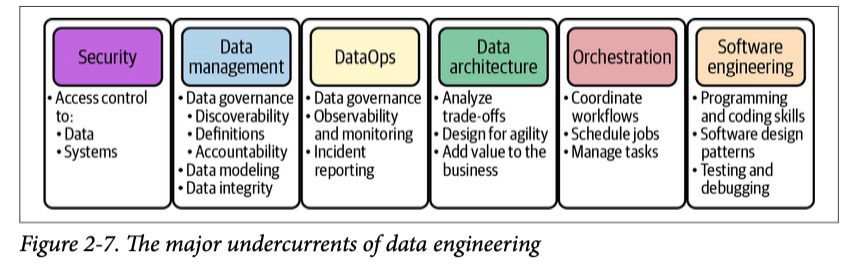
Фундаментом для всего жизненного цикла работы с данными являются следующие аспекты (нижняя часть диаграммы 1-1): безопасность, управление данными, DataOps, архитектура данных, оркестрация, software engineering.
Дата инженер в процессе жизненного цикла работы с данными должен преследовать следующие цели:
— обеспечить максимальную окупаемость вложенных инвестиций (ROI) при разработке и минимизировать затраты как финансовые, так и связанные с упущенными возможностями
— снизить риски, связанные с безопасностью и качеством данных
— максимизировать ценность и полезность данных необходимых бизнесу
Генерация данных. Системы источники.
Системы источники — это то место где данные изначально появляются. Дата инженер потребляет данные из источников, но при этом не является владельцем и не управляет системой источником. Ему важно понимать как данная система работает и генерирует данные, включая такие параметры как: частоту генерации новых данных, скорость, разнообразие генерируемых данных, может ли потенциально привести к проблемам с производительностью системы в результате аналитических запросов.
Также дата инженеру важно поддерживать связь с владельцами источника данных, чтобы быть в курсе о любых изменениях, которые могут прервать конвейер загрузки данных. Изменения могут быть такого характера: изменение типа данных, например, смена типа колонки в таблице БД, миграция на новую БД.
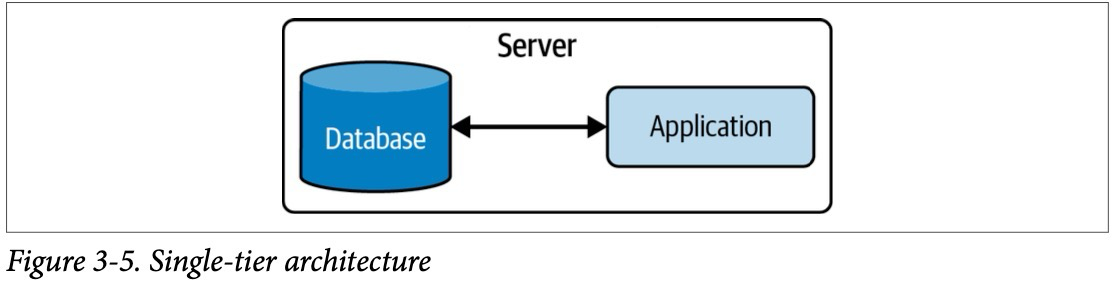
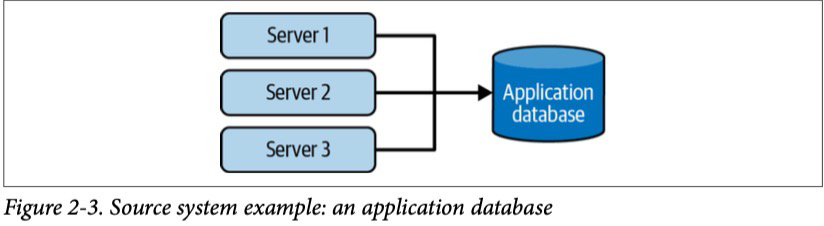
Традиционным источником хранения генерируемых данных является транзакционная база данных, в которой может хранится информация о клиентах, платежах, заказах компании и т. д.. Данный подход стал популярен в 1980-ых и до сих пор активно используется во многих популярных архитектур приложений, например, как микросервисная архитектура.
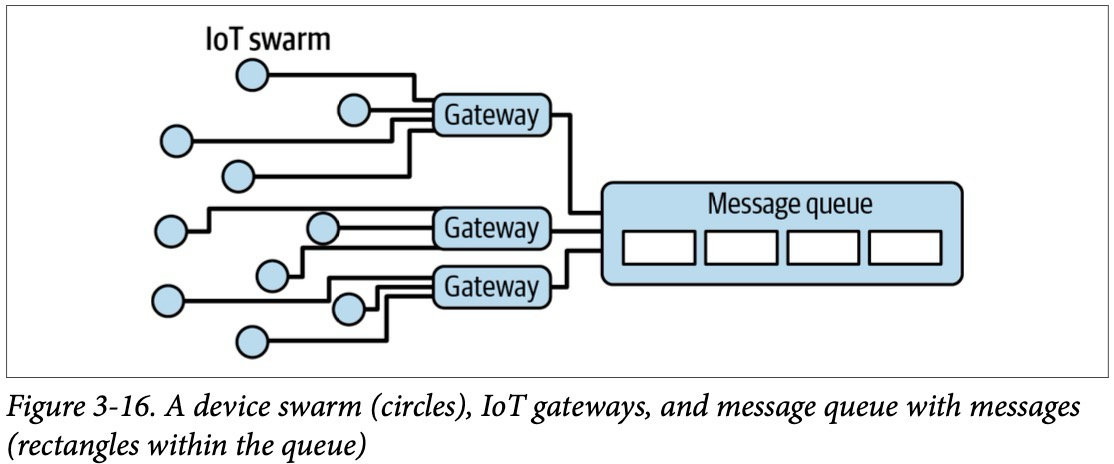
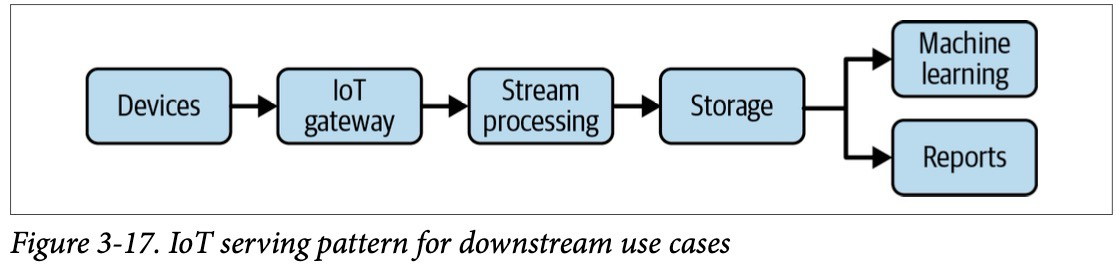
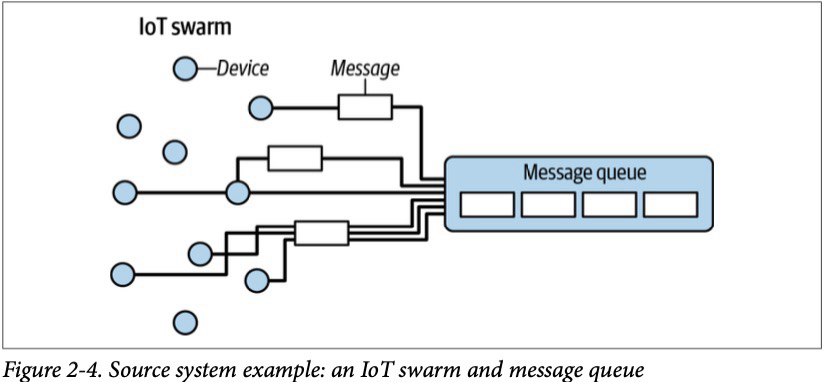
Другим и более современным источником данных является IoT (Internet of things) devices. Каждый девайс, например, смартфон генерирует данные (поведение пользователя в приложении — это новые сгенерированные данные). Данные представляются в виде сообщений, которые направляются в брокеры сообщений (транспорт данных между системами), которые аккумулируют их и передают в другие системы потребители.
Хранение данных
Решение где хранить данные очень важное, поскольку оно влияет на все этапы жизненного цикла работы с данными и взаимодействует с процессами их загрузки, преобразования и предоставления.
Частота доступа к данным
Разные типы данных имеют разные паттерны доступа в зависимости от того, как часто они извлекаются и запрашиваются. Данные классифицируются по «температуре» в зависимости от частоты доступа:
— Горячие данные. Часто запрашиваемые данные (несколько раз в день или даже в секунду), которые должны храниться для быстрого извлечения.
— Теплые данные. Запрашиваются реже, например, еженедельно или ежемесячно.
— Холодные данные. Редко запрашиваемые данные, подходящие для архивного хранения, часто сохраняемые для соблюдения требований законодательства, compliance или для восстановления после аварий.
Подход к хранению холодных данных эволюционировал, и современные облачные среды предлагают специализированные уровни хранения, которые являются экономически эффективными для долгосрочного хранения, но могут нести более высокие затраты при их извлечении.
Выбор системы хранения
Какой тип хранения данных вам следует использовать? Это зависит от ваших требований по их использованию, объема данных, частоты их поступления, формата и размера обрабатываемых данных — по сути, от ключевых факторов, перечисленных выше. Нет универсальной рекомендации по хранению, подходящей для всех. У каждой технологии хранения есть свои плюсы и минусы.
Загрузка, сбор данных
После того как удалось разобраться с источником данных и хранением данных, следующий шаг — это забор данных из системы. Источники данных и процессы их забора часто являются узкими горлышками в жизненном цикле работы с данными. Источники данных обычно находятся вне вашего контроля и могут стать недоступными или начать предоставлять некачественные данные. Сервисы, что загружают данные, также могут неожиданно выходить из строя, что вызывает проблемы с конвейером данных. Ненадежные источники и системы загрузки данных создают цепную реакцию проблем по всему жизненному циклу работы с данными.
Пакетная обработка против потоковой обработки
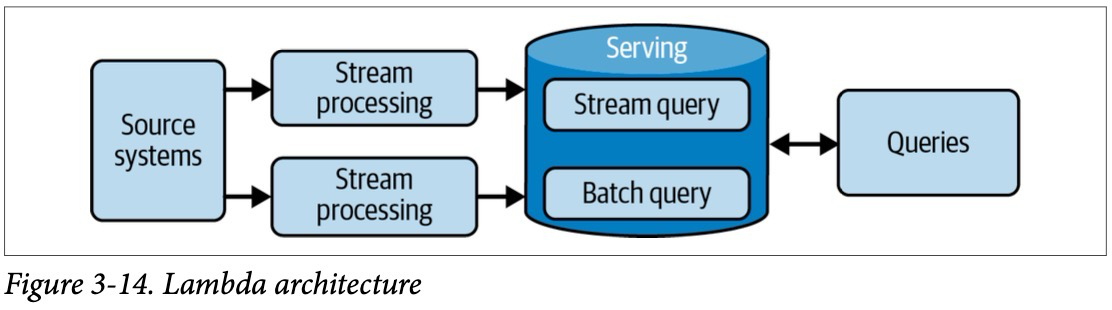
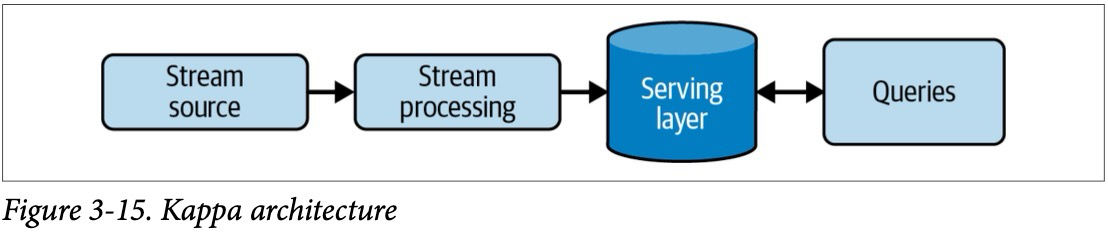
Данные постоянно генерируются и обновляются на источнике в реальном времени. Пакетная обработка больших объемов данных, например, ежедневная загрузка, часто применяется в устаревших системах. Загрузка данных через пакетную обработку задается в заранее установленные временные интервалы или в тот момент когда накапливаемые данные достигнут установленных порогов по объему. Из-за ограничений старых систем пакетная загрузка долгое время была стандартным способом обработки данных. Тем не менее, пакетная обработка по-прежнему остается очень популярным методом загрузки данных для аналитики и машинного обучения. В свою очередь, потоковая загрузка позволяет передавать данные конечным потребителям в режиме реального времени или близком к реальному с минимальной задержкой (например, менее одной секунды). Современные платформы потоковой обработки данных и разделение процесса хранения и вычисления во многих современных системах способствуют доступности и росту популярности обработки данных в реальном времени. Выбор между пакетной и потоковой обработкой зависит от конкретных задач и ожиданиями по времени готовности данных для обработки в системах потребителях.
Подход с потоковой обработкой данных может показаться хорошей идеей, но это не всегда так. Пакетная обработка является отличным подходом для многих распространенных случаев, таких как обучение моделей и еженедельная отчетность. Используйте потоковую обработку в реальном времени только после того, как выявите бизнес-сценарий, который оправдывает затраты и риски по сравнению с использованием пакетной обработки.
Модель Push и Pull данных
В моделе push источник отправляет данные непосредственно в целевую систему, будь то база данных, объектное хранилище или файловая система. В модели pull данные извлекаются из источника.
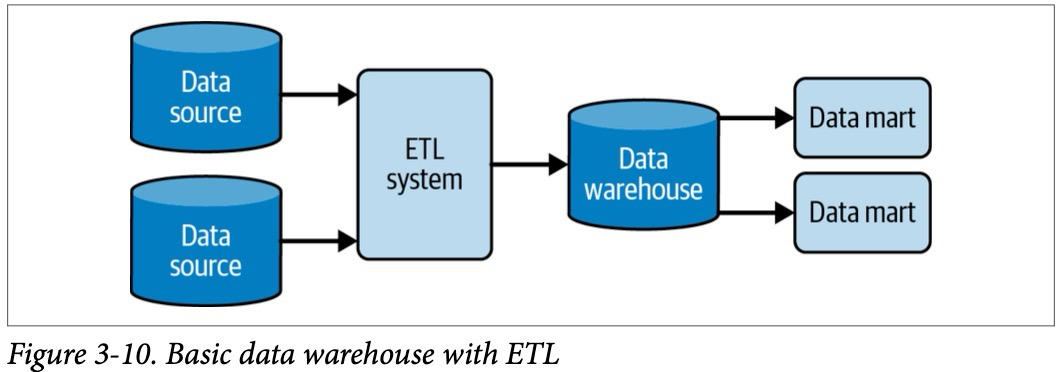
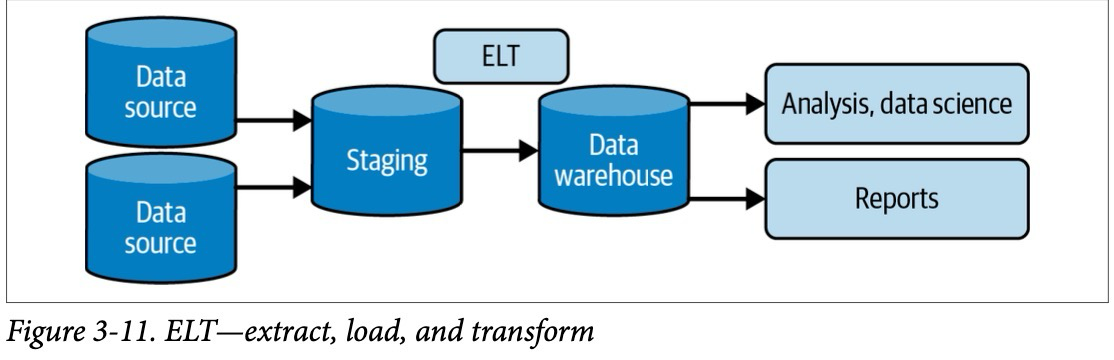
Рассмотрим, к примеру, процесс извлечения, преобразования и загрузки данных (ETL), который часто используется в пакетных потоках загрузки данных. Часть процесса ETL, отвечающая за извлечение (E), подчеркивает, что мы имеем дело с моделью Pull данных. ETL система выполняет запрос к текущей таблице-источнику по определенному расписанию.
В другом примере рассмотрим непрерывный процесс изменения данных (CDC), который достигается несколькими способами. Один из распространенных методов, когда обращаемся к каждой измененной строке в БД. Эта строка отправляется в очередь, откуда система по загрузке данных ее забирает. Другой распространенный метод CDC использует транзакционные логи, которые фиксируют каждый commit в БД. База данных записывает каждый commit в логи, а система по загрузке данных читает эти логи, не взаимодействуя с БД напрямую. Это создает минимальную или даже нулевую дополнительную нагрузку на БД. Некоторые версии пакетного CDC используют модель pull данных. Например, в случае CDC на основе временных меток система по загрузке данных делает запрос к БД и извлекает строки, которые изменились с момента последнего обновления.
Трансформация данных
На этом этапе жизненного цикла работы с данными происходит их преобразование, то есть данные изменяются из своего исходного вида во что-то полезное для дальнейшего использования. Без правильного преобразования данные останутся бесполезными и не будут пригодны для отчетов, анализа или машинного обучения. Как правило, именно на этапе преобразования данные начинают приносить пользу для конечных пользователей.
При преобразовании данных следует учитывать следующие вещи:
— Каковы затраты и выгода преобразования данных? Какую бизнес ценность она несет?
— Является ли трансформация простой, понятной и изолированной от остальных операций с данными?
— Какую бизнес логику имплементирует преобразование данных?
Преобразование данных может выполняться как в пакетном режиме, так и в потоковой обработке. Хотя пакетные преобразования остаются преобладающими, растущая популярность потоковой обработки и увеличение объема потоковых данных ведут к тому, что потоковые преобразования могут со временем вытеснить пакетные в некоторых областях.
Преобразование данных часто интегрируется с другими фазами жизненного цикла работы с данными. Оно может выполняться уже на стороне системы источника или «налету» во время загрузки данных. Пример: система может обогатить запись дополнительными системными полями в процессе загрузки.
Бизнес-логика — это основная движущая сила преобразования данных. Пример: продажа товара может быть выражена как бизнес-логика, которая переводится в конкретные и многократно переиспользуемые элементы. Моделирование данных важно для понимания и отражения бизнес-процессов, и важно обеспечивать стандартный подход к реализации бизнес-логики в процессе преобразования.
Формирование признаков для машинного обучения — это еще один процесс преобразования данных. Он предназначен для извлечения и улучшения признаков данных, полезных для обучения моделей машинного обучения. Формирование признаков может быть сложным занятием, сочетающим в себе знания в данной области (чтобы определить, какие признаки могут быть важны для прогнозирования). После определения способа формирования признаков data scientist’ами, процессы разработки признаков могут быть автоматизированы инженерами данных на этапе преобразования данных.
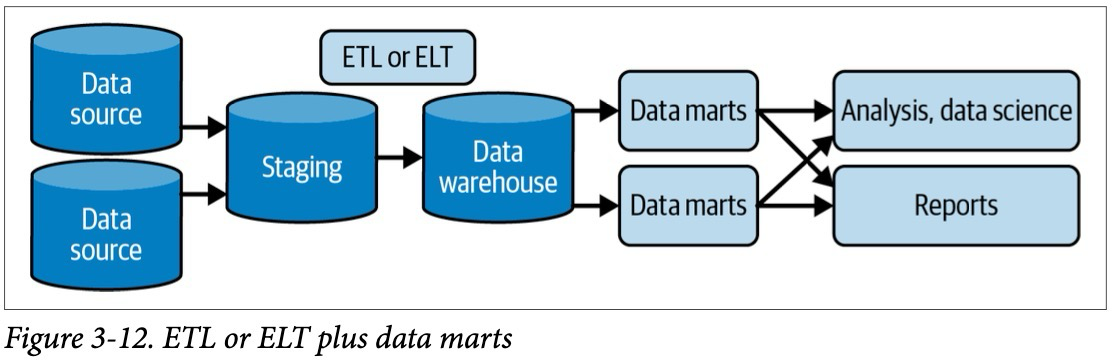
Предоставление данных конечным потребителям
Предоставление данных — это самая интересная часть жизненного цикла работы с данными. Именно здесь и происходит волшебство. Именно здесь инженеры машинного обучения могут применить самые передовые подходы. Рассмотрим некоторые из популярных видов использования данных: аналитику, машинное обучение и обратный ETL.
Аналитика
Существует два типа аналитики:
- Операционная
- Бизнес аналитика
Бизнес аналитика (BI)
Данный тип аналитики описывает состояние бизнеса компании в прошлом или в настоящем. Бизнес аналитика требует обработки сырых данных используя бизнес логику. Как мы ранее говорили процесс обработки данных по бизнес правилам происходит на этапе трансформации данных, но помимо этого все большую популярность набирает подход применение бизнес правил при чтении данных. Данные в таком случае хранятся практически в сыром виде с минимальной постобработкой по бизнес логике. BI системы, которые читают данные из хранилищ данных, хранят репозиторий знаний о бизнес логике. При запросе данных из хранилища применяется бизнес логика для составления отчетов, дашбордов.
При росте компании и зрелости данных организация переходит от случайных ad-hoc запросов к сервисам самостоятельной аналитики, то есть без вмешательства IT специалистов, где любой бизнес пользователь может подключиться к данным, покрутить данные так как ему захочется и тут же получить ценную информацию. Однако зачастую организация сервисов самостоятельной аналитики проста лишь в теории, зачастую — это сложная задача по нескольким причинам: плохое качество данных, организационная изоляция, отсутствие навыков по работе с данными.
Операционная аналитика
Операционная аналитика сфокусирована на деталях состоянии бизнеса в текущее время.
В операционной аналитике данные потребляются в реальном времени напрямую из системы источника данных или из системы потоковой обработки данных. Ценность информации, полученной от операционной аналитики, отличается от традиционной бизнес аналитики тем что операционная аналитика сфокусирована на текущем состоянии бизнеса и нет задачи в поиске трендов в исторических данных.
Машинное обучение
Машинное обучение (ML) — одна из самых значимых технологических революций наших дней. Компании, достигшие зрелости в работе с данными, могут начинать применять ML для решений задач бизнеса, формируя практики вокруг него. Однако важно не спешить и сначала построить надежный фундамент данных.
Дата инженеры часто пересекаются в обязанностях с ML-инженерами и аналитиками. Они поддерживают кластеры Spark для аналитики и ML, системы оркестрации и каталоги данных. Определение зон ответственности между инженерией данных и ML — ключевое организационное решение.
Хранилища признаков (feature stores) помогают уменьшить нагрузку на ML-инженеров, сохраняя историю и версии признаков и обеспечивая совместное их использование между командами. Инженеры данных играют важную роль в поддержке хранилищ признаков.
Инженеры данных должны понимать основы ML, связанные с ними требования к обработке данных и задачи аналитических команд. Это помогает наладить коммуникацию, сотрудничество и создавать инструменты, которые объединяют усилия команд. Перед внедрением ML важно оценить качество данных, их доступность и соответствие реальности.
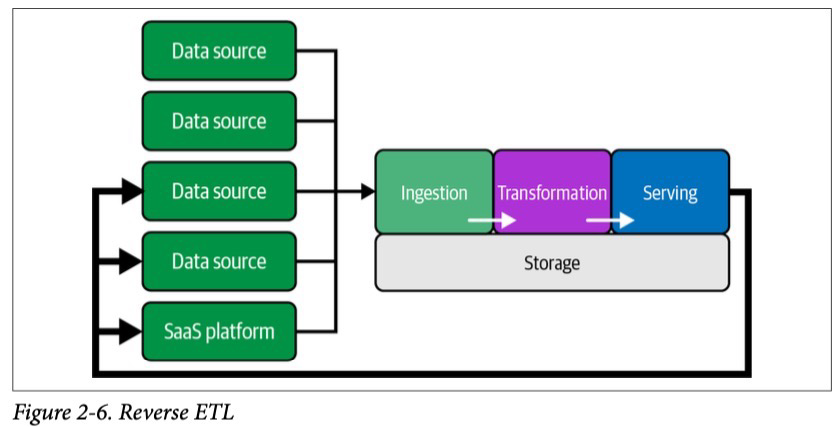
Обратный ETL
Обратный ETL — это процесс, при котором обработанные данные из хранилища данных возвращаются в исходные системы, такие как CRM или SaaS-платформы. Хотя раньше эта практика считалась нежелательной, сегодня она признаётся полезной и часто необходимой для бизнеса.
Примеры использования обратного ETL:
— Реклама и маркетинг: Аналитики рассчитывают ставки в Excel на основе данных из хранилища, а затем вручную загружают эти данные в Google Ads.
— CRM и платформы управления клиентами: Компании передают метрики и аналитические данные обратно в CRM для улучшения взаимодействия с клиентами.
— Модели и аналитика: Данные аналитики или результаты моделей машинного обучения возвращаются в системы источники для дальнейшего использования.
Основные практики, протекающие через весь жизненный цикл работы с данными
Безопасность
Проблемы безопасности в компаниях часто возникают из-за человеческого фактора, когда сотрудники пренебрегают базовыми мерами предосторожности. Это может включать в себя фишинговые атаки, слабые пароли, неправильную настройку систем безопасности или недостаточное внимание к соблюдению стандартов безопасности.
Безопасность должна быть главным приоритетом для дата инженеров, поскольку они несут ответственность за защиту данных на уровне систем и инфраструктуры. Игнорирование аспектов безопасности может привести к значительным рискам для организации, таким как утечка конфиденциальной информации или серьезные сбои в системе. Помимо технической части работы с данными, инженеры должны уделять внимание вопросам безопасности, принимая во внимание как защиту самих данных, так и контроль доступа к ним.
Принцип минимальных привилегий
Принцип минимальных привилегий предполагает предоставление пользователям и системам только того доступа, который необходим для выполнения их текущих задач. Например, если сотрудник выполняет только поиск, просмотр файлов, ему не нужно предоставлять права суперпользователя (root). Права администратора следует давать только тем пользователям, которым они действительно необходимы. Важно, чтобы доступ к данным был предоставлен только на тот период, который необходим для выполнения их задачи, чтобы минимизировать риски их утечки.
Контроль доступа и защита данных
Защита данных включает в себя не только предоставление доступа к данным только тем людям и системам, которые действительно нуждаются в них, но и обеспечение того, чтобы данные были защищены на всех этапах их использования. Данные должны быть защищены как в процессе их передачи, так и когда данные никем не используются . Это можно обеспечить с помощью таких технологий, как шифрование, токенизация, маскирование данных и использование строгих систем управления доступом.
Управление данными
Управление данными — это обеспечение качества, целостности, безопасности и удобства использования данных, собранных организацией, благодаря этому извлекается максимальная ценность из данных для бизнеса. Управление данными помогает компаниям избегать проблем с недоверием к ним и упрощает процесс принятия решений. Для эффективного управления данными необходимы люди, процессы и технологии.
Если управление данными организовано плохо, это может привести к таким ситуациям:
— Аналитик получает запрос на отчет, но не знает, какие данные использовать.
— Он тратит часы на поиск нужных таблиц, делая предположения.
— Итоговый отчет получается неполным и сомнительным.
— Это вызывает недоверие к данным в целом и осложняет бизнес-планирование
Управление данных подразделяется на следующие категории:
— Обнаружение данных (Discoverability): Возможность находить нужные данные
— Безопасность (Security): Защита данных от несанкционированного доступа.
— Ответственность (Accountability): Определение, кто отвечает за данные.
Обнаружение данных
В data-driven компании информация должна быть доступной и легко обнаруживаемой. Конечные пользователи должны иметь быстрый и надежный доступ к данным, необходимым для выполнения их работы. Они должны понимать, откуда берутся данные, как они связаны с другими данными и что эти данные означают.
Ключевые области, связанные с обнаружением данных, включают управление метаданными и управление мастер-данными
Метаданные — это данные о данных, которые являются основой для всего жизненного цикла работы с данными. Используя метаданные дата инженеры проектируют потоки данных, управляют данными через весь жизненный цикл работы с данными, и убеждаются что данные использованы правильно.
Основные категории метаданных:
— Бизнес метаданные. Позволяет понять как данные используются в бизнес контексте, включая бизнес правила, определения
— Технические метаданные. Описывают создание и использование данных в процессе инженерии данных. Включают модель данных, происхождение и схему данных.
— Операционные метаданные. Относится к операционным системам, включают статистику работы заданий, логи, отслеживание ошибок, мониторинг успешного или неуспешного выполнения заданий
— Справочная информация. Редко меняющиеся данные, которые используются для классификации других данных, например, единицы измерения, налоговые ставки, коды валют, стран и т. д. Благодаря справочным данным все источники данных в организации буду классифицировать одинаковым образом, что повышает согласованность и их качество
Мастер данные — это данные о ключевых бизнес сущностях организации, таких как сотрудники, клиенты, продукты и т. д. Управление мастер-данными (MDM) — это практики создания последовательных определений сущностей, известных как «золотые записи», поддерживающиеся технологическими инструментами, приводящие данные из разных источников, форматов к единому стандарту или структуре по всей организации. Это необходимо для обеспечения согласованности, точности и совместимости данных. Данный процесс может прямо входить в сферу ответственности дата инженеров, но часто является задачей отдельной специализированной команды. В качестве примера команда MDM может определить стандартный формат адресов клиентов, а затем работать с инженерами для создания API, который будет возвращать согласованные адреса, систем, использующие данные об адресах для сопоставления записей клиентов между подразделениями компании.
Ответственность за данные
Ответственность за данные — это назначение контактного лица для управления конкретной порции данных. Контактные лица обеспечивают согласованность, качество, доступ, корректное и понятное описание, защиту от несанкционированного доступа, соответствие регуляторным требования данных, координацию по управлению данными с другими заинтересованными лицами. Объектами, за которыми закреплены ответственные, могут быть как отдельные таблицы, потоки данных, так и конкретные поля в таблицах. Не всегда дата инженеры являются ответственными за данными, ими могут быть и software engineers, и product owners, и другие роли.
Качество данных
Качество данных — это целостный, непрерывный процесс, требующий сочетания человеческих и технологических усилий, постоянного мониторинга, проверки, обратной связи с пользователями и четких определений данных, чтобы гарантировать, что данные точны, полны, согласованы и надежны
Качество данных определяется тремя ключевыми аспектами:
— Точность: Данные должны быть правильными, без дубликатов и с точными числовыми значениями
— Полнота: Записи должны быть полными, и все необходимые поля должны содержать допустимые значения
— Согласованность: Данные должны быть согласованы в разных системах
Моделирование и проектирование данных — процесс преобразования данных в пригодную для использования форме с целью извлечения бизнес-ценности. Модель данных — модель, которая показывает как данные соотносятся с реальным миром, чтобы наилучшим образом соответствовать процессам, определениям и бизнес логике вашей организации.
Происхождение данных (Data Lineage)
По мере того как данные проходят через жизненный цикл работы с данными, они изменяются через преобразования и комбинации с другими данными. Бывает сложно понять, как был получен определенный набор данных. Инструменты происхождения данных помогают инженерам понять предыдущие шаги трансформации, а также их источники. Важно отслеживать происхождение и изменения данных, их зависимости с течением времени, потому что это помогает отслеживать ошибки, решать инциденты, находить ответственных за данные и отлаживать данные при разработке систем, которые их обрабатывают.
DataOps
DataOps — это совокупность практик, культурных норм и архитектурных паттернов.
DataOps имеет три основные технические составляющие: автоматизация, мониторинг и наблюдаемость, а также реагирование на инциденты.
Автоматизация в DataOps имеет схожий воркфлоу что и у DevOps, состоящий из управления изменениями (управление окружением, кодом и версиями данных), непрерывной интеграции и развертывания (CI/CD) и конфигурации приложения через код. Как и в DevOps, практики DataOps следят за надежностью технологий и систем (потоки данных, оркестрация и т. д.), но еще и проверкой качества данных, перекосом данных и целостностью метаданных.
Мониторинг и наблюдаемость критически важны для своевременного выявления любых проблем на протяжении всего жизненного цикла работы с данными. Мониторинг, логирование, нотификация — все это играет важную роль. Рекомендуется внедрять SPC (Statistical Process Control), чтобы понимать, являются ли отслеживаемые события отклонениями от нормы.
Реагирование на инциденты — это симбиоз использования возможностей автоматизации и мониторинга для быстрого выявления причин инцидента и устранения его последствий. Можно выделить следующие аспекты:
— Реагирование на инциденты — это не только про технологии и инструменты, но и открытая, лишенная обвинений коммуникация как среди дата инженеров, так и на уровне всей организации
— дата инженеры должны быть подготовленными к возникновению аварий и оперативно действовать для быстрого восстановления работы системы
— дата инженеры должны проактивно находить проблемы до того, как о них сообщит бизнес
Архитектура данных
Архитектура данных отражает текущее и будущее состояние дата систем, удовлетворяющих долгосрочные потребности и стратегию организации в области данных. Поскольку требования организации к данным, вероятно, будут быстро изменяться, а новые инструменты и практики появляются почти ежедневно, дата инженерам стоит разбираться в проектировании хороших архитектур данных.
Дата инженер должен понимать потребности бизнеса и собирать требования для новых случаев использования данных. Дата инженер должен уметь переводить эти требования в проектирование новых загрузок и предоставление данных конечным потребителям, учитывая баланс между стоимостью и операционными затратами. Это означает, что знание компромиссов между паттернами проектирования, технологиями и инструментами является крайне важным аспектом в работе дата инженера.
Дата инженер и архитектор данных — это две разные роли, но важно чтобы дата инженер мог реализовывать и понимать проекты архитектора данных и мог предоставлять обратную связь по архитектуре.
Оркестрация
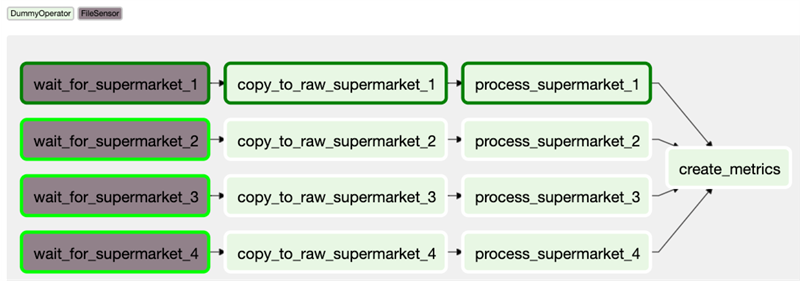
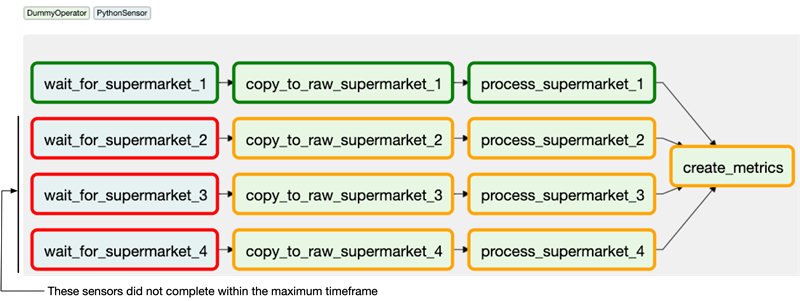
Оркестрация — это процесс координации множества заданий, чтобы они выполнялись быстро и эффективно по запланированному расписанию. Система оркестрации должна работать в режиме высокой доступности, это позволяет ей постоянно отслеживать и мониторить процессы без вмешательства человека и запускать новые задания всякий раз, когда она развертывается. Система оркестрации следит за задачами и при их успешном завершении запускает новые, анализируя их зависимости. Также она мониторит внешние системы, чтобы отслеживать поступление новых данных и выполнение необходимых условий для запуска новых заданий. Когда условия запуска заданий завершаются с ошибкой система оповещает об этом заинтересованных лиц по почте или другим каналам связи.
Software Engineering
Software Engineering всегда был ключевым навыком для дата инженеров. В ранние годы инженерии данных (2000—2010) инженеры работали с низкоуровневыми фреймворками и писали задачи MapReduce на C, C++ и Java. В разгар эпохи больших данных (середина 2010-х годов) инженеры начали использовать фреймворки, которые абстрагировались от низкоуровневых деталей. Использование абстракций продолжается и сегодня, поскольку облачные хранилища данных поддерживают мощные преобразования данных, используя SQL, Spark. Несмотря на это, software engineering по-прежнему остается критически важным аспектом для дата инженеров.
Разработка open-source фреймворков
Многие дата инженеры активно вносят вклад в разработку open-source фреймворков для решения конкретных задач в жизненном цикле обработки данных, а затем продолжают дорабатывать их код, улучшая инструменты под свои задачи и внося вклад в сообщество. Хорошими примерами таких фреймворков являются фреймворки экосистемы Hadoop и оркестратор Apache Airflow. Прежде чем дата инженеры начнут разрабатывать новые внутренние инструменты, им стоит изучить существующие решения. Есть большая вероятность, что уже существует open-source проекты, решающий их проблему, и лучше присоединиться к его развитию, чем изобретать велосипед заново.
На практике, независимо от того, какие высокоуровневые инструменты используют дата инженеры, они неизбежно сталкиваются с необычными случаями в течение жизненного цикла обработки данных, которые требуют выхода за рамки возможностей выбранных инструментов. При работе с фреймворками, такими как Fivetran, Airbyte или Matillion, дата инженеры могут столкнуться с источниками данных, для которых нет готовых коннекторов, и тогда им придется разрабатывать их самостоятельно. Для этого важно владеть навыками программирования, чтобы разбираться в API, извлекать и преобразовывать данные, обрабатывать исключения и решать другие задачи, выходящие за рамки стандартного функционала инструментов.